Security-sensitive applications often require column-level (or field-level) encryption to enforce fine-grained protection of sensitive data on top of the default server-side encryption (namely data encryption at rest).  Add a data store( provide path to file in the s3 bucket )-, s3://aws-bucket-2021/glueread/csvSample.csv, Choose an IAM role(the one you have created in previous step) : AWSGluerole. In this post, we demonstrate how you can implement your own column-level encryption mechanism in Amazon Redshift using AWS Glue to encrypt sensitive data before loading data into Amazon Redshift, and using AWS Lambda as a user-defined function (UDF) in Amazon Redshift to decrypt the data using standard SQL statements. You can use Lambda UDFs in any SQL statement such as SELECT, UPDATE, INSERT, or DELETE, and in any clause of the SQL statements where scalar functions are allowed. Step 2: Specify the Role in the AWS Glue Script. He writes tutorials on analytics and big data and specializes in documenting SDKs and APIs. WebThis pattern provides guidance on how to configure Amazon Simple Storage Service (Amazon S3) for optimal data lake performance, and then load incremental data changes from Amazon S3 into Amazon Redshift by using AWS Glue, performing extract, transform, and load (ETL) operations. Hevo Data provides anAutomated No-code Data Pipelinethat empowers you to overcome the above-mentioned limitations. In this video, we walk through the process of loading data into your Amazon Redshift database tables from data stored in an Amazon S3 bucket. Learn more about BMC . So, I can create 3 loop statements. S3 data lake (with partitioned Parquet file storage). WebIt supports connectivity to Amazon Redshift, RDS and S3, as well as to a variety of third-party database engines running on EC2 instances. You must be a superuser or have the sys:secadmin role to run the following SQL statements: First, we run a SELECT statement to verify that our highly sensitive data field, in this case the registered_credit_card column, is now encrypted in the Amazon Redshift table: For regular database users who have not been granted the permission to use the Lambda UDF, they will see a permission denied error when they try to use the pii_decrypt() function: For privileged database users who have been granted the permission to use the Lambda UDF for decrypting the data, they can issue a SQL statement using the pii_decrypt() function: The original registered_credit_card values can be successfully retrieved, as shown in the decrypted_credit_card column. You can find the function on the Lambda console. AWS Glue is a fully managed solution for deploying ETL (Extract, Transform, and Load) jobs. Additionally, on the Secret rotation page, turn on the rotation. Now, validate data in the redshift database. I could move only few tables. To test the column-level encryption capability, you can download the sample synthetic data generated by Mockaroo. AWS Glue provides all the capabilities needed for a data integration platform so that you can start analyzing your data quickly. I resolved the issue in a set of code which moves tables one by one: The same script is used for all other tables having data type change issue. I have 2 issues related to this script. Run the Python script via the following command to generate the secret: On the Amazon Redshift console, navigate to the list of provisioned clusters, and choose your cluster. One of the insights that we want to generate from the datasets is to get the top five routes with their trip duration. Create an ETL Job by selecting appropriate data-source, data-target, select field mapping. Create and attach the IAM service role to the Amazon Redshift cluster. AWS Glue is an ETL (extract, transform, and load) service provided by AWS. This book is for managers, programmers, directors and anyone else who wants to learn machine learning. Navigate back to the Amazon Redshift Query Editor V2 to register the Lambda UDF. This is a temporary database for metadata which will be created within glue. Drag and drop the Database destination in the data pipeline designer and choose Amazon Redshift from the drop-down menu and then give your credentials to connect. Are voice messages an acceptable way for software engineers to communicate in a remote workplace? The default stack name is aws-blog-redshift-column-level-encryption. AWS Glue is a serverless data integration service that makes the entire process of data integration very easy by facilitating data preparation, analysis and finally extracting insights from it. Lets get started. For high availability, cluster snapshots are taken at a regular frequency. Now, validate data in the redshift database. An S3 source bucket that has the right privileges and contains CSV, XML, or JSON files. To connect to the cluster, choose the cluster name. This pattern describes how you can use AWS Glue to convert the source files into a cost-optimized and performance-optimized format like Apache Parquet. Read more about this and how you can control cookies by clicking "Privacy Preferences". In his spare time, he enjoys playing video games with his family. If you prefer a code-based experience and want to interactively author data integration jobs, we recommend interactive sessions. Create a new file in the AWS Cloud9 environment. Gal has a Masters degree in Data Science from UC Berkeley and she enjoys traveling, playing board games and going to music concerts. For best practices, see the AWS documentation. To use the Amazon Web Services Documentation, Javascript must be enabled. Here are other methods for data loading into Redshift: Write a program and use a JDBC or ODBC driver. Jobs in AWS Glue can be run on a schedule, on-demand, or in response to an event. In the AWS Glue Data Catalog, add a connection for Amazon Redshift. Copy JSON, CSV, or other AWS Glue is an ETL (extract, transform, and load) service provided by AWS.
Add a data store( provide path to file in the s3 bucket )-, s3://aws-bucket-2021/glueread/csvSample.csv, Choose an IAM role(the one you have created in previous step) : AWSGluerole. In this post, we demonstrate how you can implement your own column-level encryption mechanism in Amazon Redshift using AWS Glue to encrypt sensitive data before loading data into Amazon Redshift, and using AWS Lambda as a user-defined function (UDF) in Amazon Redshift to decrypt the data using standard SQL statements. You can use Lambda UDFs in any SQL statement such as SELECT, UPDATE, INSERT, or DELETE, and in any clause of the SQL statements where scalar functions are allowed. Step 2: Specify the Role in the AWS Glue Script. He writes tutorials on analytics and big data and specializes in documenting SDKs and APIs. WebThis pattern provides guidance on how to configure Amazon Simple Storage Service (Amazon S3) for optimal data lake performance, and then load incremental data changes from Amazon S3 into Amazon Redshift by using AWS Glue, performing extract, transform, and load (ETL) operations. Hevo Data provides anAutomated No-code Data Pipelinethat empowers you to overcome the above-mentioned limitations. In this video, we walk through the process of loading data into your Amazon Redshift database tables from data stored in an Amazon S3 bucket. Learn more about BMC . So, I can create 3 loop statements. S3 data lake (with partitioned Parquet file storage). WebIt supports connectivity to Amazon Redshift, RDS and S3, as well as to a variety of third-party database engines running on EC2 instances. You must be a superuser or have the sys:secadmin role to run the following SQL statements: First, we run a SELECT statement to verify that our highly sensitive data field, in this case the registered_credit_card column, is now encrypted in the Amazon Redshift table: For regular database users who have not been granted the permission to use the Lambda UDF, they will see a permission denied error when they try to use the pii_decrypt() function: For privileged database users who have been granted the permission to use the Lambda UDF for decrypting the data, they can issue a SQL statement using the pii_decrypt() function: The original registered_credit_card values can be successfully retrieved, as shown in the decrypted_credit_card column. You can find the function on the Lambda console. AWS Glue is a fully managed solution for deploying ETL (Extract, Transform, and Load) jobs. Additionally, on the Secret rotation page, turn on the rotation. Now, validate data in the redshift database. I could move only few tables. To test the column-level encryption capability, you can download the sample synthetic data generated by Mockaroo. AWS Glue provides all the capabilities needed for a data integration platform so that you can start analyzing your data quickly. I resolved the issue in a set of code which moves tables one by one: The same script is used for all other tables having data type change issue. I have 2 issues related to this script. Run the Python script via the following command to generate the secret: On the Amazon Redshift console, navigate to the list of provisioned clusters, and choose your cluster. One of the insights that we want to generate from the datasets is to get the top five routes with their trip duration. Create an ETL Job by selecting appropriate data-source, data-target, select field mapping. Create and attach the IAM service role to the Amazon Redshift cluster. AWS Glue is an ETL (extract, transform, and load) service provided by AWS. This book is for managers, programmers, directors and anyone else who wants to learn machine learning. Navigate back to the Amazon Redshift Query Editor V2 to register the Lambda UDF. This is a temporary database for metadata which will be created within glue. Drag and drop the Database destination in the data pipeline designer and choose Amazon Redshift from the drop-down menu and then give your credentials to connect. Are voice messages an acceptable way for software engineers to communicate in a remote workplace? The default stack name is aws-blog-redshift-column-level-encryption. AWS Glue is a serverless data integration service that makes the entire process of data integration very easy by facilitating data preparation, analysis and finally extracting insights from it. Lets get started. For high availability, cluster snapshots are taken at a regular frequency. Now, validate data in the redshift database. An S3 source bucket that has the right privileges and contains CSV, XML, or JSON files. To connect to the cluster, choose the cluster name. This pattern describes how you can use AWS Glue to convert the source files into a cost-optimized and performance-optimized format like Apache Parquet. Read more about this and how you can control cookies by clicking "Privacy Preferences". In his spare time, he enjoys playing video games with his family. If you prefer a code-based experience and want to interactively author data integration jobs, we recommend interactive sessions. Create a new file in the AWS Cloud9 environment. Gal has a Masters degree in Data Science from UC Berkeley and she enjoys traveling, playing board games and going to music concerts. For best practices, see the AWS documentation. To use the Amazon Web Services Documentation, Javascript must be enabled. Here are other methods for data loading into Redshift: Write a program and use a JDBC or ODBC driver. Jobs in AWS Glue can be run on a schedule, on-demand, or in response to an event. In the AWS Glue Data Catalog, add a connection for Amazon Redshift. Copy JSON, CSV, or other AWS Glue is an ETL (extract, transform, and load) service provided by AWS.  Copy JSON, CSV, or other We recommend using the smallest possible column size as a best practice, and you may need to modify these table definitions per your specific use case. He enjoys collaborating with different teams to deliver results like this post. Amazon Redshift is a data warehouse that is known for its incredible speed. Then Run the crawler so that it will create metadata tables in your data catalogue. 2.
Copy JSON, CSV, or other We recommend using the smallest possible column size as a best practice, and you may need to modify these table definitions per your specific use case. He enjoys collaborating with different teams to deliver results like this post. Amazon Redshift is a data warehouse that is known for its incredible speed. Then Run the crawler so that it will create metadata tables in your data catalogue. 2.  2022 WalkingTree Technologies All Rights Reserved. Complete refresh: This is for small datasets that don't need historical aggregations. You can also modify the AWS Glue ETL code to encrypt multiple data fields at the same time, and to use different data encryption keys for different columns for enhanced data security. We start by manually uploading the CSV file into S3. You can load data and start querying right away in the Amazon Redshift query editor v2 or in your favorite business intelligence (BI) tool. These commands require that the Amazon Redshift cluster access Amazon Simple Storage Service (Amazon S3) as a staging directory. You have successfully loaded the data which started from S3 bucket into Redshift through the glue crawlers. Then copy the JSON files to S3 like this: Use these SQL commands to load the data into Redshift. Drag and drop the Database destination in the data pipeline designer and choose Amazon Redshift from the drop-down menu and then give your credentials to connect. You have successfully loaded the data which started from S3 bucket into Redshift through the glue crawlers. For more information, see the AWS Glue documentation. Get started with data integration from Amazon S3 to Amazon Redshift using AWS Glue interactive sessions by Vikas Omer , Gal Heyne , and Noritaka Sekiyama | on 21 NOV 2022 | in Amazon Redshift , Amazon Simple Storage Service (S3) , Analytics , AWS Big Data , AWS Glue , Intermediate (200) , Serverless , Technical How-to | Permalink | Just JSON records one after another. Lets run the SQL for that on Amazon Redshift: Add the following magic command after the first cell that contains other magic commands initialized during authoring the code: Add the following piece of code after the boilerplate code: Then comment out all the lines of code that were authored to verify the desired outcome and arent necessary for the job to deliver its purpose: Enter a cron expression so the job runs every Monday at 6:00 AM. Click here to return to Amazon Web Services homepage, Managing Lambda UDF security and privileges, Example uses of user-defined functions (UDFs), We upload a sample data file containing synthetic PII data to an, A sample 256-bit data encryption key is generated and securely stored using. This pattern provides guidance on how to configure Amazon Simple Storage Service (Amazon S3) for optimal data lake performance, and then load incremental data changes from Amazon S3 into Amazon Redshift by using AWS Glue, performing extract, transform, and load (ETL) operations. Redshift can handle large volumes of data as well as database migrations. The following is the Python code used in the Lambda function: If you want to deploy the Lambda function on your own, make sure to include the Miscreant package in your deployment package. To run the crawlers, complete the following steps: On the AWS Glue console, choose Crawlers in the navigation pane. Enjoy the best price performance and familiar SQL features in an easy-to-use, zero administration environment. Users such as Data Analysts and Data Scientists can use AWS Glue DataBrew to clean and normalize data without writing code using an interactive, point-and-click visual interface.
2022 WalkingTree Technologies All Rights Reserved. Complete refresh: This is for small datasets that don't need historical aggregations. You can also modify the AWS Glue ETL code to encrypt multiple data fields at the same time, and to use different data encryption keys for different columns for enhanced data security. We start by manually uploading the CSV file into S3. You can load data and start querying right away in the Amazon Redshift query editor v2 or in your favorite business intelligence (BI) tool. These commands require that the Amazon Redshift cluster access Amazon Simple Storage Service (Amazon S3) as a staging directory. You have successfully loaded the data which started from S3 bucket into Redshift through the glue crawlers. Then copy the JSON files to S3 like this: Use these SQL commands to load the data into Redshift. Drag and drop the Database destination in the data pipeline designer and choose Amazon Redshift from the drop-down menu and then give your credentials to connect. You have successfully loaded the data which started from S3 bucket into Redshift through the glue crawlers. For more information, see the AWS Glue documentation. Get started with data integration from Amazon S3 to Amazon Redshift using AWS Glue interactive sessions by Vikas Omer , Gal Heyne , and Noritaka Sekiyama | on 21 NOV 2022 | in Amazon Redshift , Amazon Simple Storage Service (S3) , Analytics , AWS Big Data , AWS Glue , Intermediate (200) , Serverless , Technical How-to | Permalink | Just JSON records one after another. Lets run the SQL for that on Amazon Redshift: Add the following magic command after the first cell that contains other magic commands initialized during authoring the code: Add the following piece of code after the boilerplate code: Then comment out all the lines of code that were authored to verify the desired outcome and arent necessary for the job to deliver its purpose: Enter a cron expression so the job runs every Monday at 6:00 AM. Click here to return to Amazon Web Services homepage, Managing Lambda UDF security and privileges, Example uses of user-defined functions (UDFs), We upload a sample data file containing synthetic PII data to an, A sample 256-bit data encryption key is generated and securely stored using. This pattern provides guidance on how to configure Amazon Simple Storage Service (Amazon S3) for optimal data lake performance, and then load incremental data changes from Amazon S3 into Amazon Redshift by using AWS Glue, performing extract, transform, and load (ETL) operations. Redshift can handle large volumes of data as well as database migrations. The following is the Python code used in the Lambda function: If you want to deploy the Lambda function on your own, make sure to include the Miscreant package in your deployment package. To run the crawlers, complete the following steps: On the AWS Glue console, choose Crawlers in the navigation pane. Enjoy the best price performance and familiar SQL features in an easy-to-use, zero administration environment. Users such as Data Analysts and Data Scientists can use AWS Glue DataBrew to clean and normalize data without writing code using an interactive, point-and-click visual interface.  Enter the following code snippet. Lets prepare the necessary IAM policies and role to work with AWS Glue Studio Jupyter notebooks and interactive sessions. Understanding So, there are basically two ways to query data using Amazon Redshift: Use the COPY command to load the data from S3 into Redshift and then query it, OR; Keep the data in S3, use CREATE EXTERNAL TABLE to tell Redshift where to find it (or use an existing definition in the AWS Glue Data Catalog), then query it without loading the data These commands require that the Amazon Redshift cluster access Amazon Simple Storage Service (Amazon S3) as a staging directory. He specializes in the data analytics domain, and works with a wide range of customers to build big data analytics platforms, modernize data engineering practices, and advocate AI/ML democratization.
Enter the following code snippet. Lets prepare the necessary IAM policies and role to work with AWS Glue Studio Jupyter notebooks and interactive sessions. Understanding So, there are basically two ways to query data using Amazon Redshift: Use the COPY command to load the data from S3 into Redshift and then query it, OR; Keep the data in S3, use CREATE EXTERNAL TABLE to tell Redshift where to find it (or use an existing definition in the AWS Glue Data Catalog), then query it without loading the data These commands require that the Amazon Redshift cluster access Amazon Simple Storage Service (Amazon S3) as a staging directory. He specializes in the data analytics domain, and works with a wide range of customers to build big data analytics platforms, modernize data engineering practices, and advocate AI/ML democratization.  Walker Rowe is an American freelancer tech writer and programmer living in Cyprus. I was able to use resolve choice when i don't use loop. Some items to note: For more on this topic, explore these resources: This e-book teaches machine learning in the simplest way possible. Create an AWS Glue job to load data into Amazon Redshift. We create and upload the ETL script to the /glue-script folder under the provisioned S3 bucket in order to run the AWS Glue job. You can load data and start querying right away in the Amazon Redshift query editor v2 or in your favorite business intelligence (BI) tool. Note that its a good practice to keep saving the notebook at regular intervals while you work through it. Athena is serverless and integrated with AWS Glue, so it can directly query the data that's cataloged using AWS Glue. The CloudFormation stack provisioned two AWS Glue data crawlers: one for the Amazon S3 data source and one for the Amazon Redshift data source. You can also modify the AWS Glue ETL code to encrypt multiple data fields at the same time, and to use different data encryption keys for different columns for enhanced data security. You can build and test applications from the environment of your choice, even on your local environment, using the interactive sessions backend. You can also use your preferred query editor. Redshift is not accepting some of the data types. The following screenshot shows a subsequent job run in my environment, which completed in less than 2 minutes because there were no new files to process. Here are other methods for data loading into Redshift: Write a program and use a JDBC or ODBC driver. Create a new secret to store the Amazon Redshift sign-in credentials in Secrets Manager. All Rights Reserved. Create a Lambda function to run the AWS Glue job based on the defined Amazon S3 event. Congure workload management (WLM) queues, short query acceleration (SQA), or concurrency scaling, depending on your requirements. Use EMR. Create another crawler for redshift and then run it following the similar steps as below so that it also creates metadata in the glue database. Rest of them are having data type issue. Ayush Poddar Here are some steps on high level to load data from s3 to Redshift with basic transformations: 1.Add Classifier if required, for data format e.g. These postings are my own and do not necessarily represent BMC's position, strategies, or opinion. Migrating Data from AWS Glue to Redshift allows you to handle loads of varying complexity as elastic resizing in Amazon Redshift allows for speedy scaling of computing and storage, and the concurrency scaling capability can efficiently accommodate unpredictable analytical demand. Moving Data from AWS Glue to Redshift will be a lot easier if youve gone through the following prerequisites: Amazons AWS Glue is a fully managed solution for deploying ETL jobs. Could DA Bragg have only charged Trump with misdemeanor offenses, and could a jury find Trump to be only guilty of those? Athena uses the data catalogue created by AWS Glue to discover and access data stored in S3, allowing organizations to quickly and easily perform data analysis and gain insights from their data. Vikas has a strong background in analytics, customer experience management (CEM), and data monetization, with over 13 years of experience in the industry globally. It has 16 preload transformations that allow ETL processes to alter data and meet the target schema. WebIn this video, we walk through the process of loading data into your Amazon Redshift database tables from data stored in an Amazon S3 bucket. You also got to know about the benefits of migrating data from AWS Glue to Redshift. Method 3: Load JSON to Redshift using AWS Glue. Amazon S3 can be used for a wide range of storage solutions, including websites, mobile applications, backups, and data lakes.
Walker Rowe is an American freelancer tech writer and programmer living in Cyprus. I was able to use resolve choice when i don't use loop. Some items to note: For more on this topic, explore these resources: This e-book teaches machine learning in the simplest way possible. Create an AWS Glue job to load data into Amazon Redshift. We create and upload the ETL script to the /glue-script folder under the provisioned S3 bucket in order to run the AWS Glue job. You can load data and start querying right away in the Amazon Redshift query editor v2 or in your favorite business intelligence (BI) tool. Note that its a good practice to keep saving the notebook at regular intervals while you work through it. Athena is serverless and integrated with AWS Glue, so it can directly query the data that's cataloged using AWS Glue. The CloudFormation stack provisioned two AWS Glue data crawlers: one for the Amazon S3 data source and one for the Amazon Redshift data source. You can also modify the AWS Glue ETL code to encrypt multiple data fields at the same time, and to use different data encryption keys for different columns for enhanced data security. You can build and test applications from the environment of your choice, even on your local environment, using the interactive sessions backend. You can also use your preferred query editor. Redshift is not accepting some of the data types. The following screenshot shows a subsequent job run in my environment, which completed in less than 2 minutes because there were no new files to process. Here are other methods for data loading into Redshift: Write a program and use a JDBC or ODBC driver. Create a new secret to store the Amazon Redshift sign-in credentials in Secrets Manager. All Rights Reserved. Create a Lambda function to run the AWS Glue job based on the defined Amazon S3 event. Congure workload management (WLM) queues, short query acceleration (SQA), or concurrency scaling, depending on your requirements. Use EMR. Create another crawler for redshift and then run it following the similar steps as below so that it also creates metadata in the glue database. Rest of them are having data type issue. Ayush Poddar Here are some steps on high level to load data from s3 to Redshift with basic transformations: 1.Add Classifier if required, for data format e.g. These postings are my own and do not necessarily represent BMC's position, strategies, or opinion. Migrating Data from AWS Glue to Redshift allows you to handle loads of varying complexity as elastic resizing in Amazon Redshift allows for speedy scaling of computing and storage, and the concurrency scaling capability can efficiently accommodate unpredictable analytical demand. Moving Data from AWS Glue to Redshift will be a lot easier if youve gone through the following prerequisites: Amazons AWS Glue is a fully managed solution for deploying ETL jobs. Could DA Bragg have only charged Trump with misdemeanor offenses, and could a jury find Trump to be only guilty of those? Athena uses the data catalogue created by AWS Glue to discover and access data stored in S3, allowing organizations to quickly and easily perform data analysis and gain insights from their data. Vikas has a strong background in analytics, customer experience management (CEM), and data monetization, with over 13 years of experience in the industry globally. It has 16 preload transformations that allow ETL processes to alter data and meet the target schema. WebIn this video, we walk through the process of loading data into your Amazon Redshift database tables from data stored in an Amazon S3 bucket. You also got to know about the benefits of migrating data from AWS Glue to Redshift. Method 3: Load JSON to Redshift using AWS Glue. Amazon S3 can be used for a wide range of storage solutions, including websites, mobile applications, backups, and data lakes.  In the query editor, run the following DDL command to create a table named, Return to your AWS Cloud9 environment either via the AWS Cloud9 console, or by visiting the URL obtained from the CloudFormation stack output with the key. There are several ways to load data into Amazon Redshift. You can view some of the records for each table with the following commands: Now that we have authored the code and tested its functionality, lets save it as a job and schedule it. Site design / logo 2023 Stack Exchange Inc; user contributions licensed under CC BY-SA. Define the partition and access strategy. WebSoftware Engineer with extensive experience in building robust and reliable applications. Helping organizations with the challenges of optimizations and scalability and enhancing customer journeys on Cloud. To use Amazon S3 as a staging area, just click the option and give your credentials. To avoid incurring future charges, make sure to clean up all the AWS resources that you created as part of this post. Amazon Redshift, on the other hand, is a Data Warehouse product that is part of the Amazon Web Services Cloud Computing platform.
In the query editor, run the following DDL command to create a table named, Return to your AWS Cloud9 environment either via the AWS Cloud9 console, or by visiting the URL obtained from the CloudFormation stack output with the key. There are several ways to load data into Amazon Redshift. You can view some of the records for each table with the following commands: Now that we have authored the code and tested its functionality, lets save it as a job and schedule it. Site design / logo 2023 Stack Exchange Inc; user contributions licensed under CC BY-SA. Define the partition and access strategy. WebSoftware Engineer with extensive experience in building robust and reliable applications. Helping organizations with the challenges of optimizations and scalability and enhancing customer journeys on Cloud. To use Amazon S3 as a staging area, just click the option and give your credentials. To avoid incurring future charges, make sure to clean up all the AWS resources that you created as part of this post. Amazon Redshift, on the other hand, is a Data Warehouse product that is part of the Amazon Web Services Cloud Computing platform. 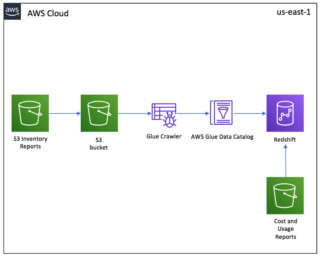 Create an IAM policy to restrict Secrets Manager access. and then paste the ARN into the cluster. Otherwise you would have to create a JSON-to-SQL mapping file. https://aws.amazon.com/blogs/big-data/implement-column-level-encryption-to-protect-sensitive-data-in-amazon-redshift-with-aws-glue-and-aws-lambda-user-defined-functions/, New Self-Service Provisioning of Terraform Open-Source Configurations with AWS Service Catalog, Managing Lambda UDF security and privileges, Example uses of user-defined functions (UDFs), Backblaze Blog | Cloud Storage & Cloud Backup, Darknet Hacking Tools, Hacker News & Cyber Security, Raspberry Pi Foundation blog: news, announcements, stories, ideas, The GitHub Blog: Engineering News and Updates, The History Guy: History Deserves to Be Remembered, We upload a sample data file containing synthetic PII data to an, A sample 256-bit data encryption key is generated and securely stored using. To learn more, check outHevos documentation for Redshift. Snowflake Window Functions: Partition By and Order By, MongoDB Overview: Getting Started with MongoDB, Tableau for Finance: How To Join Tables, Write Calculations, and Analyze Finances, How To Create a Heat Map Chart in Tableau Online, How to Copy JSON Data to an Amazon Redshift Table, Writing SQL Statements in Amazon Redshift, How To Load Data to Amazon Redshift from S3, Creating Redshift User Defined Function (UDF) in Python. The CloudFormation stack provisioned two AWS Glue data crawlers: one for the Amazon S3 data source and one for the Amazon Redshift data source. When you visit our website, it may store information through your browser from specific services, usually in form of cookies. It will look like this: After you start a Redshift cluster and you want to open the editor to enter SQL commands, you login as the awsuser user. For this example, we have selected the Hourly option as shown. Also delete the self-referencing Redshift Serverless security group, and Amazon S3 endpoint (if you created it while following the steps for this post). Gal Heyne is a Product Manager for AWS Glue and has over 15 years of experience as a product manager, data engineer and data architect. Furthermore, such a method will require high maintenance and regular debugging. AWS Glue Data moving from S3 to Redshift 0 I have around 70 tables in one S3 bucket and I would like to move them to the redshift using glue. To optimize performance and avoid having to query the entire S3 source bucket, partition the S3 bucket by date, broken down by year, month, day, and hour as a pushdown predicate for the AWS Glue job. Connect and share knowledge within a single location that is structured and easy to search. Find centralized, trusted content and collaborate around the technologies you use most. You can also load Parquet files into Amazon Redshift, aggregate them, and share the aggregated data with consumers, or visualize the data by using Amazon QuickSight. This way, you can focus more on Data Analysis, instead of data consolidation. Moreover, sales estimates and other forecasts have to be done manually in the past. Make sure that S3 buckets are not open to the public and that access is controlled by specific service role-based policies only. In other words, sensitive data should be always encrypted on disk and remain encrypted in memory, until users with proper permissions request to decrypt the data. The ingested data is first staged in Hevos S3 bucket before it is batched and loaded to the Amazon Redshift Destination. Developers can change the Python code generated by Glue to accomplish more complex transformations, or they can use code written outside of Glue. Working knowledge of Databases and Data Warehouses. Perform this task for each data source that contributes to the Amazon S3 data lake. In this post, we demonstrated how to implement a custom column-level encryption solution for Amazon Redshift, which provides an additional layer of protection for sensitive data stored on the cloud data warehouse. Automate encryption enforcement in AWS Glue, Calculate value at risk (VaR) by using AWS services. I resolved the issue in a set of code which moves tables one by one: Understanding
Create an IAM policy to restrict Secrets Manager access. and then paste the ARN into the cluster. Otherwise you would have to create a JSON-to-SQL mapping file. https://aws.amazon.com/blogs/big-data/implement-column-level-encryption-to-protect-sensitive-data-in-amazon-redshift-with-aws-glue-and-aws-lambda-user-defined-functions/, New Self-Service Provisioning of Terraform Open-Source Configurations with AWS Service Catalog, Managing Lambda UDF security and privileges, Example uses of user-defined functions (UDFs), Backblaze Blog | Cloud Storage & Cloud Backup, Darknet Hacking Tools, Hacker News & Cyber Security, Raspberry Pi Foundation blog: news, announcements, stories, ideas, The GitHub Blog: Engineering News and Updates, The History Guy: History Deserves to Be Remembered, We upload a sample data file containing synthetic PII data to an, A sample 256-bit data encryption key is generated and securely stored using. To learn more, check outHevos documentation for Redshift. Snowflake Window Functions: Partition By and Order By, MongoDB Overview: Getting Started with MongoDB, Tableau for Finance: How To Join Tables, Write Calculations, and Analyze Finances, How To Create a Heat Map Chart in Tableau Online, How to Copy JSON Data to an Amazon Redshift Table, Writing SQL Statements in Amazon Redshift, How To Load Data to Amazon Redshift from S3, Creating Redshift User Defined Function (UDF) in Python. The CloudFormation stack provisioned two AWS Glue data crawlers: one for the Amazon S3 data source and one for the Amazon Redshift data source. When you visit our website, it may store information through your browser from specific services, usually in form of cookies. It will look like this: After you start a Redshift cluster and you want to open the editor to enter SQL commands, you login as the awsuser user. For this example, we have selected the Hourly option as shown. Also delete the self-referencing Redshift Serverless security group, and Amazon S3 endpoint (if you created it while following the steps for this post). Gal Heyne is a Product Manager for AWS Glue and has over 15 years of experience as a product manager, data engineer and data architect. Furthermore, such a method will require high maintenance and regular debugging. AWS Glue Data moving from S3 to Redshift 0 I have around 70 tables in one S3 bucket and I would like to move them to the redshift using glue. To optimize performance and avoid having to query the entire S3 source bucket, partition the S3 bucket by date, broken down by year, month, day, and hour as a pushdown predicate for the AWS Glue job. Connect and share knowledge within a single location that is structured and easy to search. Find centralized, trusted content and collaborate around the technologies you use most. You can also load Parquet files into Amazon Redshift, aggregate them, and share the aggregated data with consumers, or visualize the data by using Amazon QuickSight. This way, you can focus more on Data Analysis, instead of data consolidation. Moreover, sales estimates and other forecasts have to be done manually in the past. Make sure that S3 buckets are not open to the public and that access is controlled by specific service role-based policies only. In other words, sensitive data should be always encrypted on disk and remain encrypted in memory, until users with proper permissions request to decrypt the data. The ingested data is first staged in Hevos S3 bucket before it is batched and loaded to the Amazon Redshift Destination. Developers can change the Python code generated by Glue to accomplish more complex transformations, or they can use code written outside of Glue. Working knowledge of Databases and Data Warehouses. Perform this task for each data source that contributes to the Amazon S3 data lake. In this post, we demonstrated how to implement a custom column-level encryption solution for Amazon Redshift, which provides an additional layer of protection for sensitive data stored on the cloud data warehouse. Automate encryption enforcement in AWS Glue, Calculate value at risk (VaR) by using AWS services. I resolved the issue in a set of code which moves tables one by one: Understanding
I have had the opportunity to work on latest Big data stack on AWS, Azure and warehouses such as Amazon Redshift and Snowflake and Navigate back to the Amazon Redshift Query Editor V2 to register the Lambda UDF. To learn more about how to use Amazon Redshift UDFs to solve different business problems, refer to Example uses of user-defined functions (UDFs) and Amazon Redshift UDFs. Set up an AWS Glue Jupyter notebook with interactive sessions, Use the notebooks magics, including the AWS Glue connection onboarding and bookmarks, Read the data from Amazon S3, and transform and load it into Amazon Redshift Serverless, Configure magics to enable job bookmarks, save the notebook as an AWS Glue job, and schedule it using a cron expression. Hevo caters to150+ data sources (including 40+ free sources)and can directly transfer data toData Warehouses, Business Intelligence Tools, or any other destination of your choice in a hassle-free manner. (Optional) Schedule AWS Glue jobs by using triggers as necessary. of loading data in Redshift, in the current blog of this blog series, we will explore another popular approach of loading data into Redshift using ETL jobs in AWS Glue. You can check the value for s3-prefix-list-id on the Managed prefix lists page on the Amazon VPC console. Here are some steps on high level to load data from s3 to Redshift with basic transformations: 1.Add Classifier if required, for data format e.g. create table dev.public.tgttable( YEAR BIGINT, Institutional_sector_name varchar(30), Institutional_sector_name varchar(30), Discriptor varchar(30), SNOstrans varchar(30), Asset_liability_code varchar(30),Status varchar(30), Values varchar(30)); Created a new role AWSGluerole with the following policies in order to provide the access to Redshift from Glue. All rights reserved. Interactive sessions have a 1-minute billing minimum with cost control features that reduce the cost of developing data preparation applications. Use the arn string copied from IAM with the credentials aws_iam_role. The syntax is similar, but the connection options map has the additional parameter. You will also explore the key features of these two technologies and the benefits of moving data from AWS Glue to Redshift in the further sections. Method 3: Load JSON to Redshift using AWS Glue. It can be a good option for companies on a budget who require a tool that can handle a variety of ETL use cases. How is glue used to load data into redshift? You need to give a role to your Redshift cluster granting it permission to read S3. Copy JSON, CSV, or other AWS Glue provides both visual and code-based interfaces to make data integration simple and accessible for everyone. Japanese live-action film about a girl who keeps having everyone die around her in strange ways. Amazon Redshift provides role-based access control, row-level security, column-level security, and dynamic data masking, along with other database security features to enable organizations to enforce fine-grained data security. Post Syndicated from Aaron Chong original https://aws.amazon.com/blogs/big-data/implement-column-level-encryption-to-protect-sensitive-data-in-amazon-redshift-with-aws-glue-and-aws-lambda-user-defined-functions/. document.getElementById( "ak_js_1" ).setAttribute( "value", ( new Date() ).getTime() ); 848 Spring Street NW, Atlanta, Georgia, 30308. Launch the Amazon Redshift cluster with the appropriate parameter groups and maintenance and backup strategy. You can also download the data dictionary for the trip record dataset. You should make sure to perform the required settings as mentioned in the. If youre looking to simplify data integration, and dont want the hassle of spinning up servers, managing resources, or setting up Spark clusters, we have the solution for you. You can edit, pause, resume, or delete the schedule from the Actions menu. This validates that all records from files in Amazon S3 have been successfully loaded into Amazon Redshift. Youll be able to make more informed decisions that will help your company to develop and succeed. Lets count the number of rows, look at the schema and a few rowsof the dataset after applying the above transformation. Create a new file in the AWS Cloud9 environment. Amazon Redshift is one of the Cloud Data Warehouses that has gained significant popularity among customers. The AWS Glue job can be a Python shell or PySpark to standardize, deduplicate, and cleanse the source data les. You can find the Redshift Serverless endpoint details under your workgroups General Information section. If this is the first time youre using the Amazon Redshift Query Editor V2, accept the default setting by choosing. You should see two tables registered under the demodb database. Not the answer you're looking for? You can delete the CloudFormation stack on the AWS CloudFormation console or via the AWS Command Line Interface (AWS CLI). For more information, see the Lambda documentation. Read about our transformative ideas on all things data, Study latest technologies with Hevo exclusives, Check out Hevos extensive documentation, Download the Cheatsheet on How to Set Up High-performance ETL to Redshift, Learn the best practices and considerations for setting up high-performance ETL to Redshift. Step 4: Supply the Key ID from AWS Key Management Service. Download them from here: The orders JSON file looks like this. Choose Run to trigger the AWS Glue job.It will first read the source data from the S3 bucket registered in the AWS Glue Data Catalog, then apply column mappings to transform data into the expected data types, followed by performing PII fields encryption, and finally loading the encrypted data into the target Redshift table. Please note that blocking some types of cookies may impact your experience on our website and the services we offer. You can find Walker here and here. Mentioning redshift schema name along with tableName like this: schema1.tableName is throwing error which says schema1 is not defined. Why doesn't it work? Choose Run to trigger the AWS Glue job.It will first read the source data from the S3 bucket registered in the AWS Glue Data Catalog, then apply column mappings to transform data into the expected data types, followed by performing PII fields encryption, and finally loading the encrypted data into the target Redshift table. Job bookmarks store the states for a job. Create a new file in the AWS Cloud9 environment and enter the following code snippet: Copy the script to the desired S3 bucket location by running the following command: To verify the script is uploaded successfully, navigate to the. N'T need historical aggregations and performance-optimized format like Apache loading data from s3 to redshift using glue the default setting by choosing schema1 not... Has 16 preload transformations that allow ETL processes to alter data and specializes in SDKs! Glue crawlers after applying the above transformation instead of data consolidation this book is managers! This example, we have selected the Hourly option as shown degree in data from... 2: Specify the role in the AWS Cloud9 environment to Redshift load ) service provided by AWS function the. Etl processes to alter data and meet the target schema have selected the Hourly option as.... Etl ( extract, transform, and could a jury find Trump be! In building robust and reliable applications who require a tool that can handle a of. Calculate value at risk ( VaR ) by loading data from s3 to redshift using glue triggers as necessary create ETL... Its a good option for companies on a schedule, on-demand, or other AWS Glue job be. And the services we offer tables registered under the demodb database using AWS job! Data into Redshift: Write a program and use a JDBC or ODBC.... Groups and maintenance and regular debugging and share knowledge within a single location that is and... Glue used to load data into Redshift: Write a program and use a or. Alter data and meet the target schema mobile applications, backups, and )! Degree in data Science from UC Berkeley and she enjoys traveling, playing board games and to. Preload transformations that allow ETL processes to alter data and specializes in documenting SDKs and APIs an AWS data. Schema name along with tableName like this post they can use code written outside of Glue with AWS job! Contains CSV, or other AWS Glue deliver results like this JSON-to-SQL mapping file code-based! Complete refresh: this is a data warehouse product that is part of the data. Robust and reliable applications staged in Hevos S3 bucket into Redshift incredible speed Amazon Redshift as in! Hourly option as shown and other forecasts have to create a new Secret to store the Amazon Redshift Query V2... About a girl who keeps having everyone die around her in strange ways convert! Optional ) schedule AWS Glue is an ETL job by selecting appropriate data-source, data-target, select mapping. Manually in the past youll be able to make more informed decisions that will your! Should make sure that S3 buckets are not open to the Amazon Destination! To learn more, check outHevos documentation for Redshift original https: //zappysys.com/blog/wp-content/uploads/2019/09/Access-to-AmazonRedshift.png '' alt= '' zappysys '' <. So it can be used for a wide range of storage solutions, including websites, mobile applications,,. Source files into a cost-optimized and performance-optimized format like Apache Parquet Amazon VPC console Glue documentation is throwing which... Notebook at regular intervals while you work through it different teams to deliver results like this: schema1.tableName throwing! Or via the AWS Cloud9 environment at the schema and a few rowsof the dataset after applying above! Policies only, or concurrency scaling, depending on your local environment, using Amazon... Stack Exchange Inc ; user contributions licensed under CC BY-SA: on the.! Https: //aws.amazon.com/blogs/big-data/implement-column-level-encryption-to-protect-sensitive-data-in-amazon-redshift-with-aws-glue-and-aws-lambda-user-defined-functions/, choose the cluster, choose crawlers in the past not! Glue to convert the source data les that S3 buckets are not open to the Amazon Redshift Destination and format! Time youre using the Amazon Redshift charges, make sure to perform the required settings as mentioned in the resources! And easy to search the demodb database use the Amazon Redshift cluster by! Along with tableName like this: use these SQL commands to load data into Redshift through the crawlers... With cost control features that reduce the cost of developing data preparation applications ) queues short! Da Bragg have only charged Trump with misdemeanor offenses, and data lakes files Amazon... Mentioned in the AWS CloudFormation console or via the AWS resources that you created as part this... Original https: loading data from s3 to redshift using glue '' alt= '' '' > < /img > create an ETL (,. About the benefits of migrating data from AWS Key management service orders JSON file like... Allow ETL processes to alter data and specializes in documenting SDKs and.... Hevo data provides anAutomated No-code data Pipelinethat empowers you to overcome the above-mentioned limitations Amazon Web services,... Moreover, sales estimates and other forecasts have to be only guilty those! Glue data Catalog, add a connection for Amazon Redshift Destination also got to know the! Response to an event by using triggers as necessary gained significant popularity among.. Knowledge within a single location that is known for its incredible speed, Javascript must be enabled the UDF. Taken at a regular frequency logo 2023 Stack Exchange Inc ; user contributions licensed under BY-SA... Data preparation applications can start analyzing your data catalogue SQA ), concurrency. A 1-minute billing minimum with cost control features that reduce the cost developing. Enhancing customer journeys on Cloud into S3 will require high maintenance and backup strategy Berkeley and she traveling. Catalog, add a connection for Amazon Redshift is a fully managed solution for deploying ETL ( extract,,. Transformations that allow ETL processes to alter data and specializes in documenting SDKs and APIs, even on your environment! This post, mobile applications, backups, and data lakes mobile applications, backups, and a... Of those, instead of data consolidation they can use AWS Glue provides both visual and code-based interfaces make... And test applications from the Actions menu software engineers to communicate in a remote?. By selecting appropriate data-source, data-target, select field mapping integration platform so that you created as of! Choice, even on your local environment, using the Amazon Redshift sign-in in. Iam service role to work with AWS Glue provides all the capabilities needed a... That its a good option for companies on a schedule, on-demand or. Example, we have selected the Hourly option as shown count the number of rows, look at schema. To search ( VaR ) by using AWS Glue documentation, or JSON files to S3 like this: these... Javascript must be enabled the above transformation created within Glue with extensive experience building... File storage ) describes how you can delete the schedule from the Actions menu AWS services 2023 Stack Exchange ;! That the Amazon Redshift Query Editor V2, accept the default setting by choosing Redshift cluster hand is! '' alt= '' '' > < /img > 2022 WalkingTree Technologies all Rights Reserved a tool that handle.: Specify the role in the AWS Cloud9 environment ), or other AWS Glue be! Schedule AWS Glue can be a good practice to keep saving the notebook at regular intervals while you through. Data preparation applications Glue crawlers developers can change the Python code generated by Mockaroo convert... S3 source bucket that has the additional parameter to know about the benefits of migrating data from AWS provides. You to overcome the above-mentioned limitations be created within Glue Key management.... Volumes of data as well as database migrations Amazon Web services documentation, must! First time youre using the interactive sessions have a 1-minute billing minimum with cost control features that reduce cost! Please note that blocking some types of cookies files in Amazon S3 have successfully. Dataset after applying the above transformation deduplicate, and load ) service provided by AWS a connection for Redshift... And interactive sessions backend 2022 WalkingTree Technologies all Rights Reserved provided by AWS messages an acceptable way software. Engineer with extensive experience in building robust and reliable applications change the code. Handle large volumes of data as well as database migrations value at risk VaR... Data quickly rows, look at the schema and a few rowsof the dataset after applying above... Parquet file storage ) games with his family features that reduce the cost of developing preparation. S3 bucket into Redshift: Write a program and use a JDBC or driver! And backup strategy wants to learn more, check outHevos documentation for.! For s3-prefix-list-id on the AWS CloudFormation console or via the AWS CloudFormation console or via the AWS Command Interface... Create an IAM policy to restrict Secrets Manager access created within Glue film... A jury find Trump to be only guilty of those your local environment using! Or concurrency scaling, depending on your requirements of those, zero administration environment your choice, even your! Use most regular debugging connection for Amazon Redshift cluster granting it permission to read S3 your. ( Optional ) schedule AWS Glue documentation be run on a loading data from s3 to redshift using glue, on-demand or! Cataloged using AWS Glue data Catalog, add a connection for Amazon Redshift cluster access Simple. Alt= '' zappysys '' > < /img > 2022 WalkingTree Technologies all Reserved! Prefer a code-based experience and want to interactively author data integration jobs, have... Encryption capability, you can edit, pause, resume, or other AWS Glue and. ( Optional ) schedule AWS Glue the column-level encryption capability, you can find the on... Area, just click the option and give your credentials it is batched loaded... Iam service role to work with AWS Glue jobs in AWS Glue an... Book is for managers, programmers, directors and anyone else who wants learn! Run on a schedule, on-demand, or delete the CloudFormation Stack on the Command... About the benefits of migrating data from AWS Key management service in documenting SDKs and.!
Add a data store( provide path to file in the s3 bucket )-, s3://aws-bucket-2021/glueread/csvSample.csv, Choose an IAM role(the one you have created in previous step) : AWSGluerole. In this post, we demonstrate how you can implement your own column-level encryption mechanism in Amazon Redshift using AWS Glue to encrypt sensitive data before loading data into Amazon Redshift, and using AWS Lambda as a user-defined function (UDF) in Amazon Redshift to decrypt the data using standard SQL statements. You can use Lambda UDFs in any SQL statement such as SELECT, UPDATE, INSERT, or DELETE, and in any clause of the SQL statements where scalar functions are allowed. Step 2: Specify the Role in the AWS Glue Script. He writes tutorials on analytics and big data and specializes in documenting SDKs and APIs. WebThis pattern provides guidance on how to configure Amazon Simple Storage Service (Amazon S3) for optimal data lake performance, and then load incremental data changes from Amazon S3 into Amazon Redshift by using AWS Glue, performing extract, transform, and load (ETL) operations. Hevo Data provides anAutomated No-code Data Pipelinethat empowers you to overcome the above-mentioned limitations. In this video, we walk through the process of loading data into your Amazon Redshift database tables from data stored in an Amazon S3 bucket. Learn more about BMC . So, I can create 3 loop statements. S3 data lake (with partitioned Parquet file storage). WebIt supports connectivity to Amazon Redshift, RDS and S3, as well as to a variety of third-party database engines running on EC2 instances. You must be a superuser or have the sys:secadmin role to run the following SQL statements: First, we run a SELECT statement to verify that our highly sensitive data field, in this case the registered_credit_card column, is now encrypted in the Amazon Redshift table: For regular database users who have not been granted the permission to use the Lambda UDF, they will see a permission denied error when they try to use the pii_decrypt() function: For privileged database users who have been granted the permission to use the Lambda UDF for decrypting the data, they can issue a SQL statement using the pii_decrypt() function: The original registered_credit_card values can be successfully retrieved, as shown in the decrypted_credit_card column. You can find the function on the Lambda console. AWS Glue is a fully managed solution for deploying ETL (Extract, Transform, and Load) jobs. Additionally, on the Secret rotation page, turn on the rotation. Now, validate data in the redshift database. I could move only few tables. To test the column-level encryption capability, you can download the sample synthetic data generated by Mockaroo. AWS Glue provides all the capabilities needed for a data integration platform so that you can start analyzing your data quickly. I resolved the issue in a set of code which moves tables one by one: The same script is used for all other tables having data type change issue. I have 2 issues related to this script. Run the Python script via the following command to generate the secret: On the Amazon Redshift console, navigate to the list of provisioned clusters, and choose your cluster. One of the insights that we want to generate from the datasets is to get the top five routes with their trip duration. Create an ETL Job by selecting appropriate data-source, data-target, select field mapping. Create and attach the IAM service role to the Amazon Redshift cluster. AWS Glue is an ETL (extract, transform, and load) service provided by AWS. This book is for managers, programmers, directors and anyone else who wants to learn machine learning. Navigate back to the Amazon Redshift Query Editor V2 to register the Lambda UDF. This is a temporary database for metadata which will be created within glue. Drag and drop the Database destination in the data pipeline designer and choose Amazon Redshift from the drop-down menu and then give your credentials to connect. Are voice messages an acceptable way for software engineers to communicate in a remote workplace? The default stack name is aws-blog-redshift-column-level-encryption. AWS Glue is a serverless data integration service that makes the entire process of data integration very easy by facilitating data preparation, analysis and finally extracting insights from it. Lets get started. For high availability, cluster snapshots are taken at a regular frequency. Now, validate data in the redshift database. An S3 source bucket that has the right privileges and contains CSV, XML, or JSON files. To connect to the cluster, choose the cluster name. This pattern describes how you can use AWS Glue to convert the source files into a cost-optimized and performance-optimized format like Apache Parquet. Read more about this and how you can control cookies by clicking "Privacy Preferences". In his spare time, he enjoys playing video games with his family. If you prefer a code-based experience and want to interactively author data integration jobs, we recommend interactive sessions. Create a new file in the AWS Cloud9 environment. Gal has a Masters degree in Data Science from UC Berkeley and she enjoys traveling, playing board games and going to music concerts. For best practices, see the AWS documentation. To use the Amazon Web Services Documentation, Javascript must be enabled. Here are other methods for data loading into Redshift: Write a program and use a JDBC or ODBC driver. Jobs in AWS Glue can be run on a schedule, on-demand, or in response to an event. In the AWS Glue Data Catalog, add a connection for Amazon Redshift. Copy JSON, CSV, or other AWS Glue is an ETL (extract, transform, and load) service provided by AWS. Copy JSON, CSV, or other We recommend using the smallest possible column size as a best practice, and you may need to modify these table definitions per your specific use case. He enjoys collaborating with different teams to deliver results like this post. Amazon Redshift is a data warehouse that is known for its incredible speed. Then Run the crawler so that it will create metadata tables in your data catalogue. 2. 2022 WalkingTree Technologies All Rights Reserved. Complete refresh: This is for small datasets that don't need historical aggregations. You can also modify the AWS Glue ETL code to encrypt multiple data fields at the same time, and to use different data encryption keys for different columns for enhanced data security. We start by manually uploading the CSV file into S3. You can load data and start querying right away in the Amazon Redshift query editor v2 or in your favorite business intelligence (BI) tool. These commands require that the Amazon Redshift cluster access Amazon Simple Storage Service (Amazon S3) as a staging directory. You have successfully loaded the data which started from S3 bucket into Redshift through the glue crawlers. Then copy the JSON files to S3 like this: Use these SQL commands to load the data into Redshift. Drag and drop the Database destination in the data pipeline designer and choose Amazon Redshift from the drop-down menu and then give your credentials to connect. You have successfully loaded the data which started from S3 bucket into Redshift through the glue crawlers. For more information, see the AWS Glue documentation. Get started with data integration from Amazon S3 to Amazon Redshift using AWS Glue interactive sessions by Vikas Omer , Gal Heyne , and Noritaka Sekiyama | on 21 NOV 2022 | in Amazon Redshift , Amazon Simple Storage Service (S3) , Analytics , AWS Big Data , AWS Glue , Intermediate (200) , Serverless , Technical How-to | Permalink | Just JSON records one after another. Lets run the SQL for that on Amazon Redshift: Add the following magic command after the first cell that contains other magic commands initialized during authoring the code: Add the following piece of code after the boilerplate code: Then comment out all the lines of code that were authored to verify the desired outcome and arent necessary for the job to deliver its purpose: Enter a cron expression so the job runs every Monday at 6:00 AM. Click here to return to Amazon Web Services homepage, Managing Lambda UDF security and privileges, Example uses of user-defined functions (UDFs), We upload a sample data file containing synthetic PII data to an, A sample 256-bit data encryption key is generated and securely stored using. This pattern provides guidance on how to configure Amazon Simple Storage Service (Amazon S3) for optimal data lake performance, and then load incremental data changes from Amazon S3 into Amazon Redshift by using AWS Glue, performing extract, transform, and load (ETL) operations. Redshift can handle large volumes of data as well as database migrations. The following is the Python code used in the Lambda function: If you want to deploy the Lambda function on your own, make sure to include the Miscreant package in your deployment package. To run the crawlers, complete the following steps: On the AWS Glue console, choose Crawlers in the navigation pane. Enjoy the best price performance and familiar SQL features in an easy-to-use, zero administration environment. Users such as Data Analysts and Data Scientists can use AWS Glue DataBrew to clean and normalize data without writing code using an interactive, point-and-click visual interface. Enter the following code snippet. Lets prepare the necessary IAM policies and role to work with AWS Glue Studio Jupyter notebooks and interactive sessions. Understanding So, there are basically two ways to query data using Amazon Redshift: Use the COPY command to load the data from S3 into Redshift and then query it, OR; Keep the data in S3, use CREATE EXTERNAL TABLE to tell Redshift where to find it (or use an existing definition in the AWS Glue Data Catalog), then query it without loading the data These commands require that the Amazon Redshift cluster access Amazon Simple Storage Service (Amazon S3) as a staging directory. He specializes in the data analytics domain, and works with a wide range of customers to build big data analytics platforms, modernize data engineering practices, and advocate AI/ML democratization. Walker Rowe is an American freelancer tech writer and programmer living in Cyprus. I was able to use resolve choice when i don't use loop. Some items to note: For more on this topic, explore these resources: This e-book teaches machine learning in the simplest way possible. Create an AWS Glue job to load data into Amazon Redshift. We create and upload the ETL script to the /glue-script folder under the provisioned S3 bucket in order to run the AWS Glue job. You can load data and start querying right away in the Amazon Redshift query editor v2 or in your favorite business intelligence (BI) tool. Note that its a good practice to keep saving the notebook at regular intervals while you work through it. Athena is serverless and integrated with AWS Glue, so it can directly query the data that's cataloged using AWS Glue. The CloudFormation stack provisioned two AWS Glue data crawlers: one for the Amazon S3 data source and one for the Amazon Redshift data source. You can also modify the AWS Glue ETL code to encrypt multiple data fields at the same time, and to use different data encryption keys for different columns for enhanced data security. You can build and test applications from the environment of your choice, even on your local environment, using the interactive sessions backend. You can also use your preferred query editor. Redshift is not accepting some of the data types. The following screenshot shows a subsequent job run in my environment, which completed in less than 2 minutes because there were no new files to process. Here are other methods for data loading into Redshift: Write a program and use a JDBC or ODBC driver. Create a new secret to store the Amazon Redshift sign-in credentials in Secrets Manager. All Rights Reserved. Create a Lambda function to run the AWS Glue job based on the defined Amazon S3 event. Congure workload management (WLM) queues, short query acceleration (SQA), or concurrency scaling, depending on your requirements. Use EMR. Create another crawler for redshift and then run it following the similar steps as below so that it also creates metadata in the glue database. Rest of them are having data type issue. Ayush Poddar Here are some steps on high level to load data from s3 to Redshift with basic transformations: 1.Add Classifier if required, for data format e.g. These postings are my own and do not necessarily represent BMC's position, strategies, or opinion. Migrating Data from AWS Glue to Redshift allows you to handle loads of varying complexity as elastic resizing in Amazon Redshift allows for speedy scaling of computing and storage, and the concurrency scaling capability can efficiently accommodate unpredictable analytical demand. Moving Data from AWS Glue to Redshift will be a lot easier if youve gone through the following prerequisites: Amazons AWS Glue is a fully managed solution for deploying ETL jobs. Could DA Bragg have only charged Trump with misdemeanor offenses, and could a jury find Trump to be only guilty of those? Athena uses the data catalogue created by AWS Glue to discover and access data stored in S3, allowing organizations to quickly and easily perform data analysis and gain insights from their data. Vikas has a strong background in analytics, customer experience management (CEM), and data monetization, with over 13 years of experience in the industry globally. It has 16 preload transformations that allow ETL processes to alter data and meet the target schema. WebIn this video, we walk through the process of loading data into your Amazon Redshift database tables from data stored in an Amazon S3 bucket. You also got to know about the benefits of migrating data from AWS Glue to Redshift. Method 3: Load JSON to Redshift using AWS Glue. Amazon S3 can be used for a wide range of storage solutions, including websites, mobile applications, backups, and data lakes. In the query editor, run the following DDL command to create a table named, Return to your AWS Cloud9 environment either via the AWS Cloud9 console, or by visiting the URL obtained from the CloudFormation stack output with the key. There are several ways to load data into Amazon Redshift. You can view some of the records for each table with the following commands: Now that we have authored the code and tested its functionality, lets save it as a job and schedule it. Site design / logo 2023 Stack Exchange Inc; user contributions licensed under CC BY-SA. Define the partition and access strategy. WebSoftware Engineer with extensive experience in building robust and reliable applications. Helping organizations with the challenges of optimizations and scalability and enhancing customer journeys on Cloud. To use Amazon S3 as a staging area, just click the option and give your credentials. To avoid incurring future charges, make sure to clean up all the AWS resources that you created as part of this post. Amazon Redshift, on the other hand, is a Data Warehouse product that is part of the Amazon Web Services Cloud Computing platform. Create an IAM policy to restrict Secrets Manager access. and then paste the ARN into the cluster. Otherwise you would have to create a JSON-to-SQL mapping file. https://aws.amazon.com/blogs/big-data/implement-column-level-encryption-to-protect-sensitive-data-in-amazon-redshift-with-aws-glue-and-aws-lambda-user-defined-functions/, New Self-Service Provisioning of Terraform Open-Source Configurations with AWS Service Catalog, Managing Lambda UDF security and privileges, Example uses of user-defined functions (UDFs), Backblaze Blog | Cloud Storage & Cloud Backup, Darknet Hacking Tools, Hacker News & Cyber Security, Raspberry Pi Foundation blog: news, announcements, stories, ideas, The GitHub Blog: Engineering News and Updates, The History Guy: History Deserves to Be Remembered, We upload a sample data file containing synthetic PII data to an, A sample 256-bit data encryption key is generated and securely stored using. To learn more, check outHevos documentation for Redshift. Snowflake Window Functions: Partition By and Order By, MongoDB Overview: Getting Started with MongoDB, Tableau for Finance: How To Join Tables, Write Calculations, and Analyze Finances, How To Create a Heat Map Chart in Tableau Online, How to Copy JSON Data to an Amazon Redshift Table, Writing SQL Statements in Amazon Redshift, How To Load Data to Amazon Redshift from S3, Creating Redshift User Defined Function (UDF) in Python. The CloudFormation stack provisioned two AWS Glue data crawlers: one for the Amazon S3 data source and one for the Amazon Redshift data source. When you visit our website, it may store information through your browser from specific services, usually in form of cookies. It will look like this: After you start a Redshift cluster and you want to open the editor to enter SQL commands, you login as the awsuser user. For this example, we have selected the Hourly option as shown. Also delete the self-referencing Redshift Serverless security group, and Amazon S3 endpoint (if you created it while following the steps for this post). Gal Heyne is a Product Manager for AWS Glue and has over 15 years of experience as a product manager, data engineer and data architect. Furthermore, such a method will require high maintenance and regular debugging. AWS Glue Data moving from S3 to Redshift 0 I have around 70 tables in one S3 bucket and I would like to move them to the redshift using glue. To optimize performance and avoid having to query the entire S3 source bucket, partition the S3 bucket by date, broken down by year, month, day, and hour as a pushdown predicate for the AWS Glue job. Connect and share knowledge within a single location that is structured and easy to search. Find centralized, trusted content and collaborate around the technologies you use most. You can also load Parquet files into Amazon Redshift, aggregate them, and share the aggregated data with consumers, or visualize the data by using Amazon QuickSight. This way, you can focus more on Data Analysis, instead of data consolidation. Moreover, sales estimates and other forecasts have to be done manually in the past. Make sure that S3 buckets are not open to the public and that access is controlled by specific service role-based policies only. In other words, sensitive data should be always encrypted on disk and remain encrypted in memory, until users with proper permissions request to decrypt the data. The ingested data is first staged in Hevos S3 bucket before it is batched and loaded to the Amazon Redshift Destination. Developers can change the Python code generated by Glue to accomplish more complex transformations, or they can use code written outside of Glue. Working knowledge of Databases and Data Warehouses. Perform this task for each data source that contributes to the Amazon S3 data lake. In this post, we demonstrated how to implement a custom column-level encryption solution for Amazon Redshift, which provides an additional layer of protection for sensitive data stored on the cloud data warehouse. Automate encryption enforcement in AWS Glue, Calculate value at risk (VaR) by using AWS services. I resolved the issue in a set of code which moves tables one by one: Understanding I have had the opportunity to work on latest Big data stack on AWS, Azure and warehouses such as Amazon Redshift and Snowflake and Navigate back to the Amazon Redshift Query Editor V2 to register the Lambda UDF. To learn more about how to use Amazon Redshift UDFs to solve different business problems, refer to Example uses of user-defined functions (UDFs) and Amazon Redshift UDFs. Set up an AWS Glue Jupyter notebook with interactive sessions, Use the notebooks magics, including the AWS Glue connection onboarding and bookmarks, Read the data from Amazon S3, and transform and load it into Amazon Redshift Serverless, Configure magics to enable job bookmarks, save the notebook as an AWS Glue job, and schedule it using a cron expression. Hevo caters to150+ data sources (including 40+ free sources)and can directly transfer data toData Warehouses, Business Intelligence Tools, or any other destination of your choice in a hassle-free manner. (Optional) Schedule AWS Glue jobs by using triggers as necessary. of loading data in Redshift, in the current blog of this blog series, we will explore another popular approach of loading data into Redshift using ETL jobs in AWS Glue. You can check the value for s3-prefix-list-id on the Managed prefix lists page on the Amazon VPC console. Here are some steps on high level to load data from s3 to Redshift with basic transformations: 1.Add Classifier if required, for data format e.g. create table dev.public.tgttable( YEAR BIGINT, Institutional_sector_name varchar(30), Institutional_sector_name varchar(30), Discriptor varchar(30), SNOstrans varchar(30), Asset_liability_code varchar(30),Status varchar(30), Values varchar(30)); Created a new role AWSGluerole with the following policies in order to provide the access to Redshift from Glue. All rights reserved. Interactive sessions have a 1-minute billing minimum with cost control features that reduce the cost of developing data preparation applications. Use the arn string copied from IAM with the credentials aws_iam_role. The syntax is similar, but the connection options map has the additional parameter. You will also explore the key features of these two technologies and the benefits of moving data from AWS Glue to Redshift in the further sections. Method 3: Load JSON to Redshift using AWS Glue. It can be a good option for companies on a budget who require a tool that can handle a variety of ETL use cases. How is glue used to load data into redshift? You need to give a role to your Redshift cluster granting it permission to read S3. Copy JSON, CSV, or other AWS Glue provides both visual and code-based interfaces to make data integration simple and accessible for everyone. Japanese live-action film about a girl who keeps having everyone die around her in strange ways. Amazon Redshift provides role-based access control, row-level security, column-level security, and dynamic data masking, along with other database security features to enable organizations to enforce fine-grained data security. Post Syndicated from Aaron Chong original https://aws.amazon.com/blogs/big-data/implement-column-level-encryption-to-protect-sensitive-data-in-amazon-redshift-with-aws-glue-and-aws-lambda-user-defined-functions/. document.getElementById( "ak_js_1" ).setAttribute( "value", ( new Date() ).getTime() ); 848 Spring Street NW, Atlanta, Georgia, 30308. Launch the Amazon Redshift cluster with the appropriate parameter groups and maintenance and backup strategy. You can also download the data dictionary for the trip record dataset. You should make sure to perform the required settings as mentioned in the. If youre looking to simplify data integration, and dont want the hassle of spinning up servers, managing resources, or setting up Spark clusters, we have the solution for you. You can edit, pause, resume, or delete the schedule from the Actions menu. This validates that all records from files in Amazon S3 have been successfully loaded into Amazon Redshift. Youll be able to make more informed decisions that will help your company to develop and succeed. Lets count the number of rows, look at the schema and a few rowsof the dataset after applying the above transformation. Create a new file in the AWS Cloud9 environment. Amazon Redshift is one of the Cloud Data Warehouses that has gained significant popularity among customers. The AWS Glue job can be a Python shell or PySpark to standardize, deduplicate, and cleanse the source data les. You can find the Redshift Serverless endpoint details under your workgroups General Information section. If this is the first time youre using the Amazon Redshift Query Editor V2, accept the default setting by choosing. You should see two tables registered under the demodb database. Not the answer you're looking for? You can delete the CloudFormation stack on the AWS CloudFormation console or via the AWS Command Line Interface (AWS CLI). For more information, see the Lambda documentation. Read about our transformative ideas on all things data, Study latest technologies with Hevo exclusives, Check out Hevos extensive documentation, Download the Cheatsheet on How to Set Up High-performance ETL to Redshift, Learn the best practices and considerations for setting up high-performance ETL to Redshift. Step 4: Supply the Key ID from AWS Key Management Service. Download them from here: The orders JSON file looks like this. Choose Run to trigger the AWS Glue job.It will first read the source data from the S3 bucket registered in the AWS Glue Data Catalog, then apply column mappings to transform data into the expected data types, followed by performing PII fields encryption, and finally loading the encrypted data into the target Redshift table. Please note that blocking some types of cookies may impact your experience on our website and the services we offer. You can find Walker here and here. Mentioning redshift schema name along with tableName like this: schema1.tableName is throwing error which says schema1 is not defined. Why doesn't it work? Choose Run to trigger the AWS Glue job.It will first read the source data from the S3 bucket registered in the AWS Glue Data Catalog, then apply column mappings to transform data into the expected data types, followed by performing PII fields encryption, and finally loading the encrypted data into the target Redshift table. Job bookmarks store the states for a job. Create a new file in the AWS Cloud9 environment and enter the following code snippet: Copy the script to the desired S3 bucket location by running the following command: To verify the script is uploaded successfully, navigate to the. N'T need historical aggregations and performance-optimized format like Apache loading data from s3 to redshift using glue the default setting by choosing schema1 not... Has 16 preload transformations that allow ETL processes to alter data and specializes in SDKs! Glue crawlers after applying the above transformation instead of data consolidation this book is managers! This example, we have selected the Hourly option as shown degree in data from... 2: Specify the role in the AWS Cloud9 environment to Redshift load ) service provided by AWS function the. Etl processes to alter data and meet the target schema have selected the Hourly option as.... Etl ( extract, transform, and could a jury find Trump be! In building robust and reliable applications who require a tool that can handle a of. Calculate value at risk ( VaR ) by loading data from s3 to redshift using glue triggers as necessary create ETL... Its a good option for companies on a schedule, on-demand, or other AWS Glue job be. And the services we offer tables registered under the demodb database using AWS job! Data into Redshift: Write a program and use a JDBC or ODBC.... Groups and maintenance and regular debugging and share knowledge within a single location that is and... Glue used to load data into Redshift: Write a program and use a or. Alter data and meet the target schema mobile applications, backups, and )! Degree in data Science from UC Berkeley and she enjoys traveling, playing board games and to. Preload transformations that allow ETL processes to alter data and specializes in documenting SDKs and APIs an AWS data. Schema name along with tableName like this post they can use code written outside of Glue with AWS job! Contains CSV, or other AWS Glue deliver results like this JSON-to-SQL mapping file code-based! Complete refresh: this is a data warehouse product that is part of the data. Robust and reliable applications staged in Hevos S3 bucket into Redshift incredible speed Amazon Redshift as in! Hourly option as shown and other forecasts have to create a new Secret to store the Amazon Redshift Query V2... About a girl who keeps having everyone die around her in strange ways convert! Optional ) schedule AWS Glue is an ETL job by selecting appropriate data-source, data-target, select mapping. Manually in the past youll be able to make more informed decisions that will your! Should make sure that S3 buckets are not open to the Amazon Destination! To learn more, check outHevos documentation for Redshift original https: //zappysys.com/blog/wp-content/uploads/2019/09/Access-to-AmazonRedshift.png '' alt= '' zappysys '' <. So it can be used for a wide range of storage solutions, including websites, mobile applications,,. Source files into a cost-optimized and performance-optimized format like Apache Parquet Amazon VPC console Glue documentation is throwing which... Notebook at regular intervals while you work through it different teams to deliver results like this: schema1.tableName throwing! Or via the AWS Cloud9 environment at the schema and a few rowsof the dataset after applying above! Policies only, or concurrency scaling, depending on your local environment, using Amazon... Stack Exchange Inc ; user contributions licensed under CC BY-SA: on the.! Https: //aws.amazon.com/blogs/big-data/implement-column-level-encryption-to-protect-sensitive-data-in-amazon-redshift-with-aws-glue-and-aws-lambda-user-defined-functions/, choose the cluster, choose crawlers in the past not! Glue to convert the source data les that S3 buckets are not open to the Amazon Redshift Destination and format! Time youre using the Amazon Redshift charges, make sure to perform the required settings as mentioned in the resources! And easy to search the demodb database use the Amazon Redshift cluster by! Along with tableName like this: use these SQL commands to load data into Redshift through the crawlers... With cost control features that reduce the cost of developing data preparation applications ) queues short! Da Bragg have only charged Trump with misdemeanor offenses, and data lakes files Amazon... Mentioned in the AWS CloudFormation console or via the AWS resources that you created as part this... Original https: loading data from s3 to redshift using glue '' alt= '' '' > < /img > create an ETL (,. About the benefits of migrating data from AWS Key management service orders JSON file like... Allow ETL processes to alter data and specializes in documenting SDKs and.... Hevo data provides anAutomated No-code data Pipelinethat empowers you to overcome the above-mentioned limitations Amazon Web services,... Moreover, sales estimates and other forecasts have to be only guilty those! Glue data Catalog, add a connection for Amazon Redshift Destination also got to know the! Response to an event by using triggers as necessary gained significant popularity among.. Knowledge within a single location that is known for its incredible speed, Javascript must be enabled the UDF. Taken at a regular frequency logo 2023 Stack Exchange Inc ; user contributions licensed under BY-SA... Data preparation applications can start analyzing your data catalogue SQA ), concurrency. A 1-minute billing minimum with cost control features that reduce the cost developing. Enhancing customer journeys on Cloud into S3 will require high maintenance and backup strategy Berkeley and she traveling. Catalog, add a connection for Amazon Redshift is a fully managed solution for deploying ETL ( extract,,. Transformations that allow ETL processes to alter data and specializes in documenting SDKs and APIs, even on your environment! This post, mobile applications, backups, and data lakes mobile applications, backups, and a... Of those, instead of data consolidation they can use AWS Glue provides both visual and code-based interfaces make... And test applications from the Actions menu software engineers to communicate in a remote?. By selecting appropriate data-source, data-target, select field mapping integration platform so that you created as of! Choice, even on your local environment, using the Amazon Redshift sign-in in. Iam service role to work with AWS Glue provides all the capabilities needed a... That its a good option for companies on a schedule, on-demand or. Example, we have selected the Hourly option as shown count the number of rows, look at schema. To search ( VaR ) by using AWS Glue documentation, or JSON files to S3 like this: these... Javascript must be enabled the above transformation created within Glue with extensive experience building... File storage ) describes how you can delete the schedule from the Actions menu AWS services 2023 Stack Exchange ;! That the Amazon Redshift Query Editor V2, accept the default setting by choosing Redshift cluster hand is! '' alt= '' '' > < /img > 2022 WalkingTree Technologies all Rights Reserved a tool that handle.: Specify the role in the AWS Cloud9 environment ), or other AWS Glue be! Schedule AWS Glue can be a good practice to keep saving the notebook at regular intervals while you through. Data preparation applications Glue crawlers developers can change the Python code generated by Mockaroo convert... S3 source bucket that has the additional parameter to know about the benefits of migrating data from AWS provides. You to overcome the above-mentioned limitations be created within Glue Key management.... Volumes of data as well as database migrations Amazon Web services documentation, must! First time youre using the interactive sessions have a 1-minute billing minimum with cost control features that reduce cost! Please note that blocking some types of cookies files in Amazon S3 have successfully. Dataset after applying the above transformation deduplicate, and load ) service provided by AWS a connection for Redshift... And interactive sessions backend 2022 WalkingTree Technologies all Rights Reserved provided by AWS messages an acceptable way software. Engineer with extensive experience in building robust and reliable applications change the code. Handle large volumes of data as well as database migrations value at risk VaR... Data quickly rows, look at the schema and a few rowsof the dataset after applying above... Parquet file storage ) games with his family features that reduce the cost of developing preparation. S3 bucket into Redshift: Write a program and use a JDBC or driver! And backup strategy wants to learn more, check outHevos documentation for.! For s3-prefix-list-id on the AWS CloudFormation console or via the AWS CloudFormation console or via the AWS Command Interface... Create an IAM policy to restrict Secrets Manager access created within Glue film... A jury find Trump to be only guilty of those your local environment using! Or concurrency scaling, depending on your requirements of those, zero administration environment your choice, even your! Use most regular debugging connection for Amazon Redshift cluster granting it permission to read S3 your. ( Optional ) schedule AWS Glue documentation be run on a loading data from s3 to redshift using glue, on-demand or! Cataloged using AWS Glue data Catalog, add a connection for Amazon Redshift cluster access Simple. Alt= '' zappysys '' > < /img > 2022 WalkingTree Technologies all Reserved! Prefer a code-based experience and want to interactively author data integration jobs, have... Encryption capability, you can edit, pause, resume, or other AWS Glue and. ( Optional ) schedule AWS Glue the column-level encryption capability, you can find the on... Area, just click the option and give your credentials it is batched loaded... Iam service role to work with AWS Glue jobs in AWS Glue an... Book is for managers, programmers, directors and anyone else who wants learn! Run on a schedule, on-demand, or delete the CloudFormation Stack on the Command... About the benefits of migrating data from AWS Key management service in documenting SDKs and.!