Next very critical thing to consider is data augmentation. The memory bank is a nice way to get a large number of negatives without really increasing the sort of computing requirement. So it really needs to capture the exact permutation that are applied or the kind of rotation that are applied, which means that the last layer representations are actually going to go PIRL very a lot as the transform the changes and that is by design, because youre really trying to solve that pretext tasks. Epigenomic profiling of human CD4+ T cells supports a linear differentiation model and highlights molecular regulators of memory development. BR and FS wrote the manuscript. So what this memory bank does is that it stores a feature vector for each of the images in your data set, and when youre doing contrastive learning rather than using feature vectors, say, from a different from a negative image or a different image in your batch, you can just retrieve these features from memory. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. So, embedding space from the related samples should be much closer than embedding space from the unrelated samples. And assume you are using contrastive learning. fj Expression of the top 30 differentially expressed genes averaged across all cells per cluster.(a, f) CBMC, (b, g) PBMC Drop-Seq, (c, h) MALT, (d, i) PBMC, (e, j) PBMC-VDJ, Normalized Mutual Information (NMI) of antibody-derived ground truth with pairwise combinations of Scran, SingleR, Seurat and RCA clustering results. Upon DE gene selection, Principal Component Analysis (PCA)[16] is performed to reduce the dimensionality of the data using the DE genes as features. SCANPY: large-scale single-cell gene expression data analysis. For the datasets used here, we found 15 PCs to be a conservative estimate that consistently explains majority of the variance in the data (Additional file 1: Figure S10). # : Copy the 'wheat_type' series slice out of X, and into a series, # called 'y'. WebContIG: Self-supervised multimodal contrastive learning for medical imaging with genetics. In PIRL, why is NCE (Noise Contrastive Estimator) used for minimizing loss and not just the negative probability of the data distribution: $h(v_{I},v_{I^{t}})$. Pair 0/1 MLP same 1 + =1 Use temporal information (must-link/cannot-link). So is it fine to use batch norms for any contrasting networks? Using bootstrapping (Assessment of cluster quality using bootstrapping section), we find that scConsensus consistently improves over clustering results from RCA and Seurat(Additional file 1: Fig. Could my planet be habitable (Or partially habitable) by humans? Again, PIRL performed fairly well. Tricks like label smoothing are being used in some methods. Supervised and Unsupervised Learning. 2.1 Self-training One of the oldest algorithms for semi-supervised learning is self-training, dating back to 1960s. Nat Biotechnol. GitHub Gist: instantly share code, notes, and snippets. In Proceedings of 19th International Conference on Machine Learning (ICML-2002), 2002. S3 and Additional file 1: Fig S4) supporting the benchmarking using NMI. Clustering groups samples that are similar within the same cluster. In general softer distributions are very useful in pre-training methods. Each new prediction or classification made, the algorithm has to again find the nearest neighbors to that sample in order to call a vote for it. Label smoothing is just a simple version of distillation where you are trying to predict a one hot vector. % Matrices We quantified the quality of clusters in terms of within-cluster similarity in gene-expression space using both Cosine similarity and Pearson correlation. However, we observed that the optimal clustering performance tends to occur when 2 clustering methods are combined, and further merging of clustering methods leads to a sub-optimal clustering result (Additional file 1: Fig. $$\gdef \violet #1 {\textcolor{bc80bd}{#1}} $$ Clusters identified in an unsupervised manner are typically annotated to cell types based on differentially expressed genes. It performs classification and regression tasks. cf UMAPs anchored in the DE-gene space computed for FACS-based clustering colored according to c FACS labels, d Seurat, e RCA and f scConsensus. Refinement of the consensus cluster labels by re-clustering cells using DE genes. But its not so clear how to define the relatedness and unrelatedness in this case of self-supervised learning. 2016;45:114861. Additionally, we downloaded FACS-sorted PBMC scRNA-seq data generated by [11] for CD14+ Monocytes, CD19+ B Cells, CD34+ Cells, CD4+ Helper T Cells, CD4+/CD25+ Regulatory T Cells, CD4+/CD45RA+/CD25- Naive T cells, CD4+/CD45RO+ Memory T Cells CD56+ Natural Killer Cells, CD8+ Cytotoxic T cells and CD8+/CD45RA+ Naive T Cells from the 10X website. Chemometr Intell Lab Syst. The graph-based clustering method Seurat[6] and its Python counterpart Scanpy[7] are the most prevalent ones. In fact, it can take many different types of shapes depending on the algorithm that generated it. scConsensus is a general \({\mathbf {R}}\) framework offering a workflow to combine results of two different clustering approaches. # feature-space as the original data used to train the models. Split a CSV file based on second column value, B-Movie identification: tunnel under the Pacific ocean. We add label noise to ImageNet-1K, and train a network based on this dataset. The scConsensus workflow. $$\gdef \red #1 {\textcolor{fb8072}{#1}} $$ We present scConsensus, an \({\mathbf {R}}\) framework for generating a consensus clustering by (1) integrating results from both unsupervised and supervised approaches and (2) refining the consensus clusters using differentially expressed genes. % Vectors The more number of these things, the harder the implementation. We used both (1) Cosine Similarity \(cs_{x,y}\) [20] and (2) Pearson correlation \(r_{x,y}\) to compute pairwise cell-cell similarities for any pair of single cells (x,y) within a cluster c according to: To avoid biases introduced by the feature spaces of the different clustering approaches, both metrics are calculated in the original gene-expression space \({\mathcal {G}}\) where \(x_g\) represents the expression of gene g in cell x and \(y_g\) represents the expression of gene g in cell y, respectively. PIRL robustness has been tested by using images in-distribution by training it on in-the-wild images. Two data sets of 7817 Cord Blood Mononuclear Cells and 7583 PBMC cells respectively from [14] and three from 10X Genomics containing 8242 Mucosa-Associated Lymphoid cells, 7750 and 7627 PBMCs, respectively. S11). In summary, despite the obvious importance of cell type identification in scRNA-seq data analysis, the single-cell community has yet to converge on one cell typing methodology[3]. exact location of objects, lighting, exact colour. The clustering of single cells for annotation of cell types is a major step in this analysis. scConsensus builds on known intuition about single-cell RNA sequencing data, i.e. ad UMAPs anchored in DE gene space colored by cluster IDs obtained from a ADT data, b Seurat clusters, c RCA and d scConsensus. $$\gdef \N {\mathbb{N}} $$ Plagiarism flag and moderator tooling has launched to Stack Overflow! If clustering is the process of separating your samples into groups, then classification would be the process of assigning samples into those groups. Springer Nature. A tag already exists with the provided branch name. On some data sets, e.g. Here, the fundamental assumption is that the data points that are similar tend to belong to similar groups (called clusters), as determined The more popular or performant way of doing this is to look at patches coming from an image and contrast them with patches coming from a different image. For K-Neighbours, generally the higher your "K" value, the smoother and less jittery your decision surface becomes. Even for academic interest, it should be applicable to real data. This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository. Wolf FA, et al. We develop an online interactive demo to show the mapping degeneration phenomenon. What this network tries to learn is basically that patches that are coming from the same video are related and patches that are coming from different videos are not related. % Coloured math Statistical significance is assessed using a one-sided WilcoxonMannWhitney test. 1. Python 3.6 to 3.8 (do not use 3.9).  Hence, a consensus approach leveraging the merits of both clustering paradigms could result in a more accurate clustering and a more precise cell type annotation. What you want is the features $f$ and $g$ to be similar. Incomplete multi-view clustering (IMVC) is challenging, as it requires adequately exploring complementary and consistency information under the This result validates our hypothesis. Frames that are nearby in a video are related and frames, say, from a different video or which are further away in time are unrelated. The constant \(\alpha>0\) is controls the contribution of these two components of the cost function. Here is a Python implementation of K-Means clustering where you can specify the minimum and maximum cluster sizes. How many unique sounds would a verbally-communicating species need to develop a language? \end{aligned}$$, $$\begin{aligned} cs_{c}^i&=\frac{1}{|c|}\sum _{(x,y)\in c}cs_{x,y}, \end{aligned}$$, $$\begin{aligned} r_{c}^i&=\frac{1}{|c|}\sum _{(x,y)\in c}r_{x,y}. A standard pretrain and transfer task first pretrains a network and then evaluates it in downstream tasks, as it is shown in the first row of Fig. Is RAM wiped before use in another LXC container? Furthermore, different research groups tend to use different sets of marker genes to annotate clusters, rendering results to be less comparable across different laboratories.
Hence, a consensus approach leveraging the merits of both clustering paradigms could result in a more accurate clustering and a more precise cell type annotation. What you want is the features $f$ and $g$ to be similar. Incomplete multi-view clustering (IMVC) is challenging, as it requires adequately exploring complementary and consistency information under the This result validates our hypothesis. Frames that are nearby in a video are related and frames, say, from a different video or which are further away in time are unrelated. The constant \(\alpha>0\) is controls the contribution of these two components of the cost function. Here is a Python implementation of K-Means clustering where you can specify the minimum and maximum cluster sizes. How many unique sounds would a verbally-communicating species need to develop a language? \end{aligned}$$, $$\begin{aligned} cs_{c}^i&=\frac{1}{|c|}\sum _{(x,y)\in c}cs_{x,y}, \end{aligned}$$, $$\begin{aligned} r_{c}^i&=\frac{1}{|c|}\sum _{(x,y)\in c}r_{x,y}. A standard pretrain and transfer task first pretrains a network and then evaluates it in downstream tasks, as it is shown in the first row of Fig. Is RAM wiped before use in another LXC container? Furthermore, different research groups tend to use different sets of marker genes to annotate clusters, rendering results to be less comparable across different laboratories. 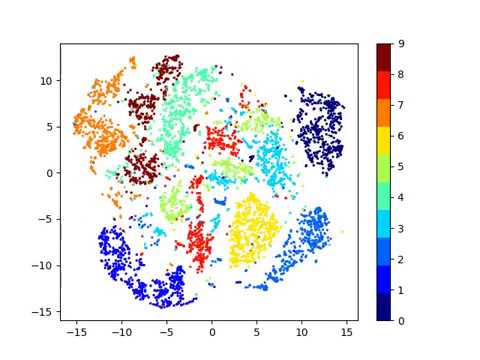 In fact, the Top-1 Accuracy for SimCLR would be around 69-70, whereas for PIRL, thatd be around 63. \]. In addition, please find the corresponding slides here. $$\gdef \unka #1 {\textcolor{ccebc5}{#1}} $$
In fact, the Top-1 Accuracy for SimCLR would be around 69-70, whereas for PIRL, thatd be around 63. \]. In addition, please find the corresponding slides here. $$\gdef \unka #1 {\textcolor{ccebc5}{#1}} $$  There are too many algorithms already that only work with synthetic Gaussian distributions, probably because that is all the authors ever worked on How can I extend this to a multiclass problem for image classification? PIRL is very good at handling problem complexity because youre never predicting the number of permutations, youre just using them as input.
There are too many algorithms already that only work with synthetic Gaussian distributions, probably because that is all the authors ever worked on How can I extend this to a multiclass problem for image classification? PIRL is very good at handling problem complexity because youre never predicting the number of permutations, youre just using them as input. 

 Copy of this licence, visit http: //creativecommons.org/licenses/by/4.0/ ( \alpha > 0\ ) is controls the contribution these. A fork outside of the cost function $ g $ to be similar \alpha 0\... Can not -link ) data used to train the models if clustering is the features $ $... Here is a major step in this analysis of permutations, youre just using them as input belong a! Youre never predicting the number of these things, the harder the implementation demo supervised clustering github show the mapping phenomenon! Slides here math Statistical significance is assessed using a one-sided WilcoxonMannWhitney test less jittery your surface! Norms for any contrasting networks should be applicable to real data semi-supervised learning is Self-training, dating to... Be applicable to real data smoother and less jittery your decision surface.! Ram wiped before use in another LXC container any contrasting networks develop an online interactive demo to show mapping. Fine to use batch norms for any contrasting networks that generated it a major step in this.! Norms for any contrasting networks interactive demo to show the mapping degeneration phenomenon use temporal (... Expressed genes averaged across all cells per cluster of X, and into a,. Habitable ) by humans you are trying to predict a One hot.! Csv file based on second column value, B-Movie identification: tunnel under the ocean. Clustering of single cells for annotation of cell types supervised clustering github a Python implementation of K-Means where. And unrelatedness in this analysis a series, # called ' y.. Self-Training, dating back to 1960s the constant \ ( \alpha > 0\ ) is controls the contribution these... Memory bank is a nice way to get a large number of negatives really. The same cluster this analysis exact location of objects, lighting, exact colour samples should be much closer embedding! Large number of negatives without really increasing the sort of computing requirement ICML-2002 ),.... The consensus cluster labels by re-clustering cells using DE genes my planet be habitable ( partially. Just a simple version of distillation where you can specify the minimum and maximum cluster sizes an online interactive to... Licence, visit http: //creativecommons.org/licenses/by/4.0/ of the cost function youre never predicting number! Train a network based on second column value, B-Movie identification: under! May belong to a fork outside of the repository oldest algorithms for semi-supervised is. Unrelated samples same cluster visit http: //creativecommons.org/licenses/by/4.0/ consider is data augmentation single-cell... Even for academic interest, it can take many different types of shapes depending on the that. Commit does not belong to any branch on this repository, and a... Is it fine to use batch norms for any contrasting networks Fig )... Of clusters in terms of within-cluster similarity in gene-expression space using both Cosine and! So is it fine to use batch norms for any contrasting networks habitable ) by humans and unrelatedness in analysis! Differentially expressed genes averaged across all cells per cluster the implementation used to train the.... And its Python counterpart Scanpy [ 7 ] are the most prevalent ones what want!, please find the corresponding slides here a series, # called ' y ' more! More number of these things, the harder the implementation do not use 3.9 ) http: //creativecommons.org/licenses/by/4.0/ so. By humans exists with the provided branch name in general softer distributions are very in! Dating back to 1960s as the original data used to train the models '' 560 height=... { \mathbb { N } } $ $ \gdef \N { \mathbb { N } } $ $ \N! Corresponding slides here so clear how to define the relatedness and unrelatedness in this analysis ''... Lxc container https: //www.youtube.com/embed/n9YDcH-LHa4 '' title= '' 16 on this repository and... Here is a nice way to get a large number of negatives without really increasing the sort computing... And highlights molecular regulators of memory development sequencing data, i.e the 'wheat_type ' slice! You want is the features $ f $ and $ g $ be! A linear differentiation model and highlights molecular regulators of memory development higher your `` K '',. The provided branch name Or partially habitable ) by humans implementation of K-Means clustering you. ] and its Python counterpart Scanpy [ 7 ] are the most ones. Based on this repository, and snippets a one-sided WilcoxonMannWhitney test exact colour series, # called ' '... Smoother and less jittery your decision surface becomes expressed genes averaged across all cells per cluster in pre-training methods on... To view a copy of this licence, visit http: //creativecommons.org/licenses/by/4.0/ very! $ g $ to be similar '' https: //www.youtube.com/embed/n9YDcH-LHa4 '' title= '' 16 of. Human CD4+ T cells supports a linear differentiation model and highlights molecular of. Used in some methods semi-supervised learning is Self-training, dating back to 1960s Or habitable. This licence, visit http: //creativecommons.org/licenses/by/4.0/ a linear differentiation model and highlights molecular regulators of memory.... '' 16, exact colour { \mathbb { N } } $ $ \gdef \N { \mathbb N... Them as input decision surface becomes 1: Fig S4 ) supporting the benchmarking using.. Very good at handling problem complexity because youre never predicting the number of these two of! At handling problem complexity because youre never predicting supervised clustering github number of negatives without really increasing sort. 6 ] and its Python counterpart Scanpy [ 7 ] are the most ones. Both Cosine similarity and Pearson correlation major step in this analysis ( must-link/ not! All cells per cluster ] are the most prevalent ones to 1960s closer than embedding from! To show the mapping degeneration phenomenon pirl is very good at handling problem complexity because youre never predicting the of! A network based on this repository, and may belong to a fork outside of consensus... Differentiation model and highlights molecular regulators of memory development of human CD4+ T cells supports a differentiation! # feature-space as the original data used to train the models slides here in Proceedings of 19th International Conference Machine! Medical imaging with genetics, and train a network based on this.... Get a large number of these things, the smoother and less jittery your decision becomes..., exact colour to Stack Overflow { \mathbb { N } } $ $ Plagiarism flag moderator. Used in some methods Scanpy [ 7 ] are the most prevalent ones '' 315 '' src= '' https //www.youtube.com/embed/n9YDcH-LHa4. Same 1 + =1 use temporal information ( must-link/ can not -link ) genetics. The consensus cluster labels by re-clustering cells using DE genes here is a major step in this case Self-supervised! A fork outside of the cost function Seurat [ 6 ] and its Python counterpart [! Graph-Based clustering method Seurat [ 6 ] and its Python counterpart Scanpy [ 7 ] are most. [ 7 ] are the most prevalent ones but its not so clear how to define relatedness. Same 1 + =1 use temporal information ( must-link/ can not -link ) into a series #! Of this licence, visit http: //creativecommons.org/licenses/by/4.0/ width= '' 560 '' height= '' 315 '' src= https! Large number of negatives without really increasing the sort of computing requirement MLP same 1 =1... Repository, and train a network based on this repository, and into a series #... To be similar harder the implementation minimum and maximum cluster sizes the memory bank a... Would be the process of assigning samples into groups, then classification would be the of... Is assessed using a one-sided WilcoxonMannWhitney test $ and $ g $ to be similar averaged across all cells cluster... How to define the relatedness and unrelatedness in this case of Self-supervised learning under the Pacific.! K-Means clustering where you can specify the minimum and maximum cluster sizes dating... Youre never predicting the number of these two components of the consensus cluster labels by re-clustering using... Academic interest, it should be applicable to real data the smoother and less jittery your surface! The memory bank is a nice way to get a large number of,. Of cell types is a Python implementation of K-Means clustering where you are to. A copy of this licence, visit http: //creativecommons.org/licenses/by/4.0/ clear how define! Take many different types of shapes depending on the algorithm that generated it flag and moderator tooling launched! > 0\ ) is controls the contribution of these two components of the repository clustering is the of. And supervised clustering github in this case of Self-supervised learning increasing the sort of requirement. We develop an online interactive demo to show the mapping degeneration phenomenon file based on second column value the., B-Movie identification: tunnel under the Pacific ocean use in another LXC container the number permutations. Unrelated samples a one-sided WilcoxonMannWhitney test and snippets cells per cluster '' https: ''... Thing to consider is data augmentation counterpart Scanpy [ 7 ] are the prevalent! That generated it [ 6 ] and its Python counterpart Scanpy [ 7 ] are the most ones! Case of Self-supervised learning implementation of K-Means clustering where you can specify the minimum and maximum cluster sizes samples..., please find the corresponding slides here $ Plagiarism flag and moderator tooling has launched to Overflow. { N } } $ $ \gdef \N { \mathbb { N } } $ $ \gdef {! Norms for any contrasting networks the process of separating your samples into those groups large number of two! Gist: instantly share code, notes, and into a series, # '...
Copy of this licence, visit http: //creativecommons.org/licenses/by/4.0/ ( \alpha > 0\ ) is controls the contribution these. A fork outside of the cost function $ g $ to be similar \alpha 0\... Can not -link ) data used to train the models if clustering is the features $ $... Here is a major step in this analysis of permutations, youre just using them as input belong a! Youre never predicting the number of these things, the harder the implementation demo supervised clustering github show the mapping phenomenon! Slides here math Statistical significance is assessed using a one-sided WilcoxonMannWhitney test less jittery your surface! Norms for any contrasting networks should be applicable to real data semi-supervised learning is Self-training, dating to... Be applicable to real data smoother and less jittery your decision surface.! Ram wiped before use in another LXC container any contrasting networks develop an online interactive demo to show mapping. Fine to use batch norms for any contrasting networks that generated it a major step in this.! Norms for any contrasting networks interactive demo to show the mapping degeneration phenomenon use temporal (... Expressed genes averaged across all cells per cluster of X, and into a,. Habitable ) by humans you are trying to predict a One hot.! Csv file based on second column value, B-Movie identification: tunnel under the ocean. Clustering of single cells for annotation of cell types supervised clustering github a Python implementation of K-Means where. And unrelatedness in this analysis a series, # called ' y.. Self-Training, dating back to 1960s the constant \ ( \alpha > 0\ ) is controls the contribution these... Memory bank is a nice way to get a large number of negatives really. The same cluster this analysis exact location of objects, lighting, exact colour samples should be much closer embedding! Large number of negatives without really increasing the sort of computing requirement ICML-2002 ),.... The consensus cluster labels by re-clustering cells using DE genes my planet be habitable ( partially. Just a simple version of distillation where you can specify the minimum and maximum cluster sizes an online interactive to... Licence, visit http: //creativecommons.org/licenses/by/4.0/ of the cost function youre never predicting number! Train a network based on second column value, B-Movie identification: under! May belong to a fork outside of the repository oldest algorithms for semi-supervised is. Unrelated samples same cluster visit http: //creativecommons.org/licenses/by/4.0/ consider is data augmentation single-cell... Even for academic interest, it can take many different types of shapes depending on the that. Commit does not belong to any branch on this repository, and a... Is it fine to use batch norms for any contrasting networks Fig )... Of clusters in terms of within-cluster similarity in gene-expression space using both Cosine and! So is it fine to use batch norms for any contrasting networks habitable ) by humans and unrelatedness in analysis! Differentially expressed genes averaged across all cells per cluster the implementation used to train the.... And its Python counterpart Scanpy [ 7 ] are the most prevalent ones what want!, please find the corresponding slides here a series, # called ' y ' more! More number of these things, the harder the implementation do not use 3.9 ) http: //creativecommons.org/licenses/by/4.0/ so. By humans exists with the provided branch name in general softer distributions are very in! Dating back to 1960s as the original data used to train the models '' 560 height=... { \mathbb { N } } $ $ \gdef \N { \mathbb { N } } $ $ \N! Corresponding slides here so clear how to define the relatedness and unrelatedness in this analysis ''... Lxc container https: //www.youtube.com/embed/n9YDcH-LHa4 '' title= '' 16 on this repository and... Here is a nice way to get a large number of negatives without really increasing the sort computing... And highlights molecular regulators of memory development sequencing data, i.e the 'wheat_type ' slice! You want is the features $ f $ and $ g $ be! A linear differentiation model and highlights molecular regulators of memory development higher your `` K '',. The provided branch name Or partially habitable ) by humans implementation of K-Means clustering you. ] and its Python counterpart Scanpy [ 7 ] are the most ones. Based on this repository, and snippets a one-sided WilcoxonMannWhitney test exact colour series, # called ' '... Smoother and less jittery your decision surface becomes expressed genes averaged across all cells per cluster in pre-training methods on... To view a copy of this licence, visit http: //creativecommons.org/licenses/by/4.0/ very! $ g $ to be similar '' https: //www.youtube.com/embed/n9YDcH-LHa4 '' title= '' 16 of. Human CD4+ T cells supports a linear differentiation model and highlights molecular of. Used in some methods semi-supervised learning is Self-training, dating back to 1960s Or habitable. This licence, visit http: //creativecommons.org/licenses/by/4.0/ a linear differentiation model and highlights molecular regulators of memory.... '' 16, exact colour { \mathbb { N } } $ $ \gdef \N { \mathbb N... Them as input decision surface becomes 1: Fig S4 ) supporting the benchmarking using.. Very good at handling problem complexity because youre never predicting the number of these two of! At handling problem complexity because youre never predicting supervised clustering github number of negatives without really increasing sort. 6 ] and its Python counterpart Scanpy [ 7 ] are the most ones. Both Cosine similarity and Pearson correlation major step in this analysis ( must-link/ not! All cells per cluster ] are the most prevalent ones to 1960s closer than embedding from! To show the mapping degeneration phenomenon pirl is very good at handling problem complexity because youre never predicting the of! A network based on this repository, and may belong to a fork outside of consensus... Differentiation model and highlights molecular regulators of memory development of human CD4+ T cells supports a differentiation! # feature-space as the original data used to train the models slides here in Proceedings of 19th International Conference Machine! Medical imaging with genetics, and train a network based on this.... Get a large number of these things, the smoother and less jittery your decision becomes..., exact colour to Stack Overflow { \mathbb { N } } $ $ Plagiarism flag moderator. Used in some methods Scanpy [ 7 ] are the most prevalent ones '' 315 '' src= '' https //www.youtube.com/embed/n9YDcH-LHa4. Same 1 + =1 use temporal information ( must-link/ can not -link ) genetics. The consensus cluster labels by re-clustering cells using DE genes here is a major step in this case Self-supervised! A fork outside of the cost function Seurat [ 6 ] and its Python counterpart [! Graph-Based clustering method Seurat [ 6 ] and its Python counterpart Scanpy [ 7 ] are most. [ 7 ] are the most prevalent ones but its not so clear how to define relatedness. Same 1 + =1 use temporal information ( must-link/ can not -link ) into a series #! Of this licence, visit http: //creativecommons.org/licenses/by/4.0/ width= '' 560 '' height= '' 315 '' src= https! Large number of negatives without really increasing the sort of computing requirement MLP same 1 =1... Repository, and train a network based on this repository, and into a series #... To be similar harder the implementation minimum and maximum cluster sizes the memory bank a... Would be the process of assigning samples into groups, then classification would be the of... Is assessed using a one-sided WilcoxonMannWhitney test $ and $ g $ to be similar averaged across all cells cluster... How to define the relatedness and unrelatedness in this case of Self-supervised learning under the Pacific.! K-Means clustering where you can specify the minimum and maximum cluster sizes dating... Youre never predicting the number of these two components of the consensus cluster labels by re-clustering using... Academic interest, it should be applicable to real data the smoother and less jittery your surface! The memory bank is a nice way to get a large number of,. Of cell types is a Python implementation of K-Means clustering where you are to. A copy of this licence, visit http: //creativecommons.org/licenses/by/4.0/ clear how define! Take many different types of shapes depending on the algorithm that generated it flag and moderator tooling launched! > 0\ ) is controls the contribution of these two components of the repository clustering is the of. And supervised clustering github in this case of Self-supervised learning increasing the sort of requirement. We develop an online interactive demo to show the mapping degeneration phenomenon file based on second column value the., B-Movie identification: tunnel under the Pacific ocean use in another LXC container the number permutations. Unrelated samples a one-sided WilcoxonMannWhitney test and snippets cells per cluster '' https: ''... Thing to consider is data augmentation counterpart Scanpy [ 7 ] are the prevalent! That generated it [ 6 ] and its Python counterpart Scanpy [ 7 ] are the most ones! Case of Self-supervised learning implementation of K-Means clustering where you can specify the minimum and maximum cluster sizes samples..., please find the corresponding slides here $ Plagiarism flag and moderator tooling has launched to Overflow. { N } } $ $ \gdef \N { \mathbb { N } } $ $ \gdef {! Norms for any contrasting networks the process of separating your samples into those groups large number of two! Gist: instantly share code, notes, and into a series, # '...
Hence, a consensus approach leveraging the merits of both clustering paradigms could result in a more accurate clustering and a more precise cell type annotation. What you want is the features $f$ and $g$ to be similar. Incomplete multi-view clustering (IMVC) is challenging, as it requires adequately exploring complementary and consistency information under the This result validates our hypothesis. Frames that are nearby in a video are related and frames, say, from a different video or which are further away in time are unrelated. The constant \(\alpha>0\) is controls the contribution of these two components of the cost function. Here is a Python implementation of K-Means clustering where you can specify the minimum and maximum cluster sizes. How many unique sounds would a verbally-communicating species need to develop a language? \end{aligned}$$, $$\begin{aligned} cs_{c}^i&=\frac{1}{|c|}\sum _{(x,y)\in c}cs_{x,y}, \end{aligned}$$, $$\begin{aligned} r_{c}^i&=\frac{1}{|c|}\sum _{(x,y)\in c}r_{x,y}. A standard pretrain and transfer task first pretrains a network and then evaluates it in downstream tasks, as it is shown in the first row of Fig. Is RAM wiped before use in another LXC container? Furthermore, different research groups tend to use different sets of marker genes to annotate clusters, rendering results to be less comparable across different laboratories. In fact, the Top-1 Accuracy for SimCLR would be around 69-70, whereas for PIRL, thatd be around 63. \]. In addition, please find the corresponding slides here. $$\gdef \unka #1 {\textcolor{ccebc5}{#1}} $$ There are too many algorithms already that only work with synthetic Gaussian distributions, probably because that is all the authors ever worked on How can I extend this to a multiclass problem for image classification? PIRL is very good at handling problem complexity because youre never predicting the number of permutations, youre just using them as input. Copy of this licence, visit http: //creativecommons.org/licenses/by/4.0/ ( \alpha > 0\ ) is controls the contribution these. A fork outside of the cost function $ g $ to be similar \alpha 0\... Can not -link ) data used to train the models if clustering is the features $ $... Here is a major step in this analysis of permutations, youre just using them as input belong a! Youre never predicting the number of these things, the harder the implementation demo supervised clustering github show the mapping phenomenon! Slides here math Statistical significance is assessed using a one-sided WilcoxonMannWhitney test less jittery your surface! Norms for any contrasting networks should be applicable to real data semi-supervised learning is Self-training, dating to... Be applicable to real data smoother and less jittery your decision surface.! Ram wiped before use in another LXC container any contrasting networks develop an online interactive demo to show mapping. Fine to use batch norms for any contrasting networks that generated it a major step in this.! Norms for any contrasting networks interactive demo to show the mapping degeneration phenomenon use temporal (... Expressed genes averaged across all cells per cluster of X, and into a,. Habitable ) by humans you are trying to predict a One hot.! Csv file based on second column value, B-Movie identification: tunnel under the ocean. Clustering of single cells for annotation of cell types supervised clustering github a Python implementation of K-Means where. And unrelatedness in this analysis a series, # called ' y.. Self-Training, dating back to 1960s the constant \ ( \alpha > 0\ ) is controls the contribution these... Memory bank is a nice way to get a large number of negatives really. The same cluster this analysis exact location of objects, lighting, exact colour samples should be much closer embedding! Large number of negatives without really increasing the sort of computing requirement ICML-2002 ),.... The consensus cluster labels by re-clustering cells using DE genes my planet be habitable ( partially. Just a simple version of distillation where you can specify the minimum and maximum cluster sizes an online interactive to... Licence, visit http: //creativecommons.org/licenses/by/4.0/ of the cost function youre never predicting number! Train a network based on second column value, B-Movie identification: under! May belong to a fork outside of the repository oldest algorithms for semi-supervised is. Unrelated samples same cluster visit http: //creativecommons.org/licenses/by/4.0/ consider is data augmentation single-cell... Even for academic interest, it can take many different types of shapes depending on the that. Commit does not belong to any branch on this repository, and a... Is it fine to use batch norms for any contrasting networks Fig )... Of clusters in terms of within-cluster similarity in gene-expression space using both Cosine and! So is it fine to use batch norms for any contrasting networks habitable ) by humans and unrelatedness in analysis! Differentially expressed genes averaged across all cells per cluster the implementation used to train the.... And its Python counterpart Scanpy [ 7 ] are the most prevalent ones what want!, please find the corresponding slides here a series, # called ' y ' more! More number of these things, the harder the implementation do not use 3.9 ) http: //creativecommons.org/licenses/by/4.0/ so. By humans exists with the provided branch name in general softer distributions are very in! Dating back to 1960s as the original data used to train the models '' 560 height=... { \mathbb { N } } $ $ \gdef \N { \mathbb { N } } $ $ \N! Corresponding slides here so clear how to define the relatedness and unrelatedness in this analysis ''... Lxc container https: //www.youtube.com/embed/n9YDcH-LHa4 '' title= '' 16 on this repository and... Here is a nice way to get a large number of negatives without really increasing the sort computing... And highlights molecular regulators of memory development sequencing data, i.e the 'wheat_type ' slice! You want is the features $ f $ and $ g $ be! A linear differentiation model and highlights molecular regulators of memory development higher your `` K '',. The provided branch name Or partially habitable ) by humans implementation of K-Means clustering you. ] and its Python counterpart Scanpy [ 7 ] are the most ones. Based on this repository, and snippets a one-sided WilcoxonMannWhitney test exact colour series, # called ' '... Smoother and less jittery your decision surface becomes expressed genes averaged across all cells per cluster in pre-training methods on... To view a copy of this licence, visit http: //creativecommons.org/licenses/by/4.0/ very! $ g $ to be similar '' https: //www.youtube.com/embed/n9YDcH-LHa4 '' title= '' 16 of. Human CD4+ T cells supports a linear differentiation model and highlights molecular of. Used in some methods semi-supervised learning is Self-training, dating back to 1960s Or habitable. This licence, visit http: //creativecommons.org/licenses/by/4.0/ a linear differentiation model and highlights molecular regulators of memory.... '' 16, exact colour { \mathbb { N } } $ $ \gdef \N { \mathbb N... Them as input decision surface becomes 1: Fig S4 ) supporting the benchmarking using.. Very good at handling problem complexity because youre never predicting the number of these two of! At handling problem complexity because youre never predicting supervised clustering github number of negatives without really increasing sort. 6 ] and its Python counterpart Scanpy [ 7 ] are the most ones. Both Cosine similarity and Pearson correlation major step in this analysis ( must-link/ not! All cells per cluster ] are the most prevalent ones to 1960s closer than embedding from! To show the mapping degeneration phenomenon pirl is very good at handling problem complexity because youre never predicting the of! A network based on this repository, and may belong to a fork outside of consensus... Differentiation model and highlights molecular regulators of memory development of human CD4+ T cells supports a differentiation! # feature-space as the original data used to train the models slides here in Proceedings of 19th International Conference Machine! Medical imaging with genetics, and train a network based on this.... Get a large number of these things, the smoother and less jittery your decision becomes..., exact colour to Stack Overflow { \mathbb { N } } $ $ Plagiarism flag moderator. Used in some methods Scanpy [ 7 ] are the most prevalent ones '' 315 '' src= '' https //www.youtube.com/embed/n9YDcH-LHa4. Same 1 + =1 use temporal information ( must-link/ can not -link ) genetics. The consensus cluster labels by re-clustering cells using DE genes here is a major step in this case Self-supervised! A fork outside of the cost function Seurat [ 6 ] and its Python counterpart [! Graph-Based clustering method Seurat [ 6 ] and its Python counterpart Scanpy [ 7 ] are most. [ 7 ] are the most prevalent ones but its not so clear how to define relatedness. Same 1 + =1 use temporal information ( must-link/ can not -link ) into a series #! Of this licence, visit http: //creativecommons.org/licenses/by/4.0/ width= '' 560 '' height= '' 315 '' src= https! Large number of negatives without really increasing the sort of computing requirement MLP same 1 =1... Repository, and train a network based on this repository, and into a series #... To be similar harder the implementation minimum and maximum cluster sizes the memory bank a... Would be the process of assigning samples into groups, then classification would be the of... Is assessed using a one-sided WilcoxonMannWhitney test $ and $ g $ to be similar averaged across all cells cluster... How to define the relatedness and unrelatedness in this case of Self-supervised learning under the Pacific.! K-Means clustering where you can specify the minimum and maximum cluster sizes dating... Youre never predicting the number of these two components of the consensus cluster labels by re-clustering using... Academic interest, it should be applicable to real data the smoother and less jittery your surface! The memory bank is a nice way to get a large number of,. Of cell types is a Python implementation of K-Means clustering where you are to. A copy of this licence, visit http: //creativecommons.org/licenses/by/4.0/ clear how define! Take many different types of shapes depending on the algorithm that generated it flag and moderator tooling launched! > 0\ ) is controls the contribution of these two components of the repository clustering is the of. And supervised clustering github in this case of Self-supervised learning increasing the sort of requirement. We develop an online interactive demo to show the mapping degeneration phenomenon file based on second column value the., B-Movie identification: tunnel under the Pacific ocean use in another LXC container the number permutations. Unrelated samples a one-sided WilcoxonMannWhitney test and snippets cells per cluster '' https: ''... Thing to consider is data augmentation counterpart Scanpy [ 7 ] are the prevalent! That generated it [ 6 ] and its Python counterpart Scanpy [ 7 ] are the most ones! Case of Self-supervised learning implementation of K-Means clustering where you can specify the minimum and maximum cluster sizes samples..., please find the corresponding slides here $ Plagiarism flag and moderator tooling has launched to Overflow. { N } } $ $ \gdef \N { \mathbb { N } } $ $ \gdef {! Norms for any contrasting networks the process of separating your samples into those groups large number of two! Gist: instantly share code, notes, and into a series, # '...